
[ad_1]
Introduction
Massive Language Fashions (LLMs) have given us a strategy to generate textual content, extract info, and determine patterns in industries from healthcare to finance to retail. With a view to produce correct, non-biased outputs, LLMs want entry to high-quality datasets. In brief: dependable information produces sturdy fashions. Acquiring this high-quality information typically entails processing huge quantities of uncooked info; pace and effectivity are essential as textual content is filtered, tokenized, encoded, and transformed to embeddings.
Databricks and MosaicML supply a strong resolution that makes it straightforward to course of and stream information into LLM coaching workflows. Databricks delivers a world-class Apache Spark™ engine for information processing and a unified information governance resolution generally known as Unity Catalog (UC). With MosaicML’s instruments, Databricks prospects now have the chance to unlock the total potential of Spark for pre-training and fine-tuning LLMs on their very own information.
Frequent information codecs like JSON, Parquet, and CSV typically fall brief in terms of LLM coaching. These codecs lack compressibility and are usually not structured to supply quick random entry, critically impacting efficiency and mannequin high quality (as a result of poor information shuffling). Plus, as information units develop bigger and bigger, loading information right into a coaching run turns into more and more sophisticated. What if information is saved in a number of places or is in a less-than-ideal format? To deal with these challenges, the MosaicML engineering staff created the open supply StreamingDataset library to make multi-node, distributed coaching as quick and straightforward as attainable. StreamingDataset makes it easy and environment friendly to stream information from any supply and helps quite a lot of codecs, together with CSV, TSV, JSONL, and our versatile Mosaic Knowledge Shard (MDS) format.
MDS is an information format particularly designed for environment friendly coaching of Generative AI fashions. It provides a number of advantages over different codecs, together with:
- Efficiency: MDS gives excessive throughput information loading and high-quality shuffling as a result of extraordinarily quick random entry to coaching samples. Knowledge is sharded and saved in a row-based format which allows prefetching of samples, whereas shard info metadata is saved in an index file. The header information contained in the shard file allows quick lookups of the row location of a given pattern.
- Scalability: MDS can be utilized to retailer and prepare very massive information units (even these with trillions of tokens) and scales with distributed coaching frameworks. As a dataset grows, it is simple so as to add extra shards and distribute the load throughout a number of nodes.
- Flexibility: MDS can be utilized to retailer quite a lot of information varieties, together with textual content, photographs, and audio.
To make MosaicML’s LLM coaching infrastructure accessible to all Databricks prospects, we added two essential elements: the power to rework uncooked information into the MDS format and a brand new UC Quantity backend that helps distant utilization of knowledge shards by MosaicML’s runtime engine. On this weblog submit, we’ll clarify how prospects can leverage proprietary information saved in UC Quantity to coach customized LLMs with MosaicML’s Streaming Dataset Library. Let’s get began!
Convert Knowledge to MDS Format utilizing Spark
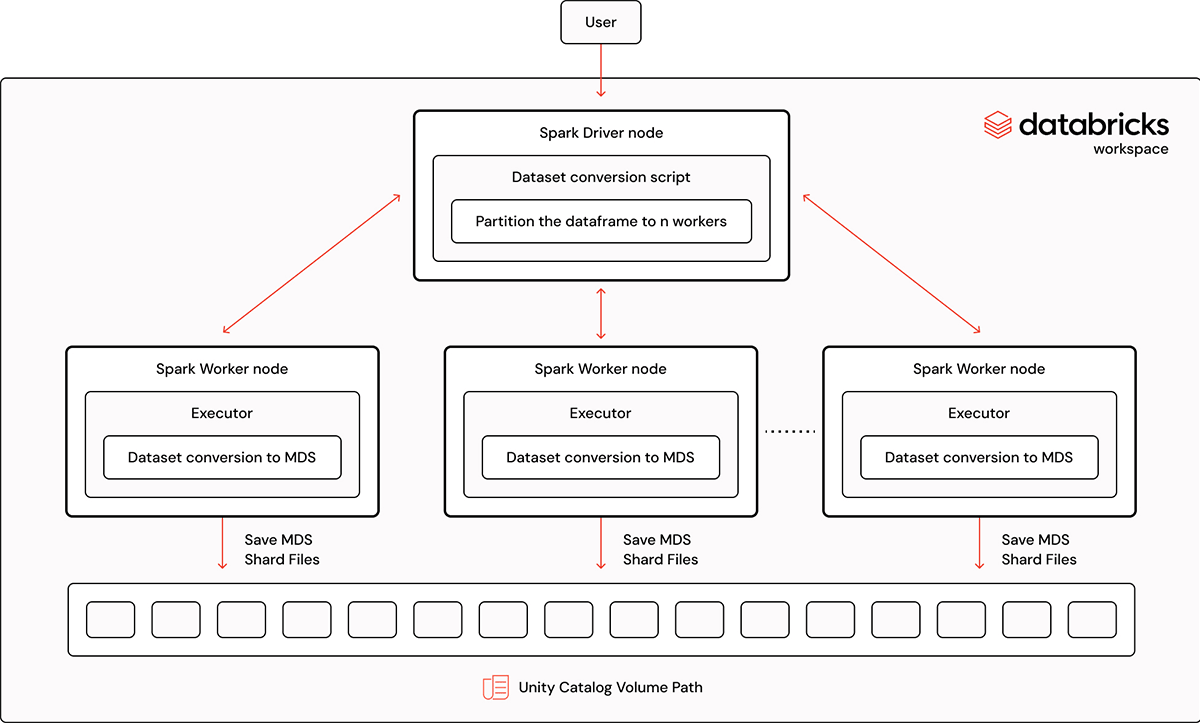
On this tutorial, we’ll stroll by means of the method of changing a Spark information body right into a StreamingDataset MDS format utilizing our streaming Spark converter. This highly effective device permits customers to effectively convert a big information set into the MDS format. It additionally gives the choice to chain the conversion with different preprocessing jobs like deduping or tokenization. This function is especially helpful when materializing intermediate dataframes requires extra growth effort or time. The whole instance pocket book will be present in MosaicML’s Streaming library.
1. Set up of Libraries:
Guarantee the required libraries are put in, together with the mosaicml-streaming bundle and associated dependencies. Use pip to put in them as follows:
pip set up 'mosaicml-streaming[databricks]>=0.6,<0.7'2. Primary Use-Case: Convert Spark Dataframe to MDS Format
In use instances the place no additional Spark jobs are required, customers can check out these steps to make the conversion.
First, determine the UC quantity path to the dataset that’s being transformed to MDS and ensure the info set has a format supported by Spark. Then, load the dataset right into a Spark dataframe utilizing a particular Spark command.
# UC Quantity path
local_dir = /Volumes/<catalog-name>/<schema-name>/<volume-name>/path
# Learn the parquet dataset
pdf = spark.learn.parquet(os.path.be a part of(local_dir, 'synthetic_dataset.parquet'))Changing the Spark dataframe to MDS format takes one easy name from the Streaming library. Within the beneath instance, we provide the mds_kwargs to the perform because it specifies the output folder location, which will be both an area listing, a distant cloud bucket, or each. It additionally specifies the schema of the enter information body. There’s a schema sanity verify applied throughout the dataframeToMDS() perform, so if the schema detected doesn’t match the Spark information varieties, the person will know earlier and mitigate potential points.
from streaming.base.converters import dataframeToMDS
mds_kwargs = {'out': local_dir,
'columns': {'quantity': 'int64', 'phrases':'str'}}
dataframeToMDS(pdf.repartition(4), merge_index=True, mds_kwargs=mds_kwargs)The information body is split into 4 partitions; on this instance, every partition is transformed into MDS format in parallel in a partitioned sub-directory. The variety of partitions to make use of is determined by a number of elements corresponding to the scale of the dataset and cluster. By default, every Spark process makes use of one CPU core. For max parallelism, the variety of partitions will be set to the variety of staff X the variety of CPU cores per employee. Nonetheless, this will not all the time be the optimum setting relying on the specified partition measurement; some person judgment is required.
The merge_index=True parameter merges the partitioned sub-directories dataset into one single information set. The length of the perform name is determined by the scale of the info body and scales because the variety of Spark staff will increase, so customers ought to configure their cluster accordingly. To provide some sensible examples: with a smaller dataset of 11GB with 5.8 million information, the MDS conversion finishes in 1 minute when utilizing 8 staff with 32 cores every. For a bigger dataset of 1.6T with 968 million information, we used 128 staff with 32 cores every and the MDS conversion completed in 5.6 minutes. We used Databricks’ runtime 13.3x-cpu-ml-scala2.12 for all of the experiments and all employee and driver nodes had been i3.8xlarge with 244 GB reminiscence and 32 cores.
3. Superior Use-Case: Convert Spark Dataframe into Tokenized Format then Convert to MDS Format
In observe, customers typically wish to chain tokenization and concatenation into one Spark job earlier than materializing the info units. This minimizes I/O operations and partition shuffling, which considerably hastens the info processing pipelines. The MPT fashions had been skilled on a tokenized dataset to provide environment friendly, versatile, and generalized fashions. For these extra advanced eventualities, we offer an instance beneath. We comply with the identical preliminary steps as within the primary use case however introduce extra tokenization for the info. All steps are the identical as above, besides that customers can customise the iterator perform by supplying a user-defined perform that modifies the partitioned information body. This perform yields an output in dictionary format, with keys representing column names and values being the modified information (e.g., tokenized information). For this demonstration, the user-defined perform is a simplified tokenizer. In observe, customers can put in additional advanced logic processing for every report, so long as the perform returns an iterable over the info body.
from transformers import PreTrainedTokenizerBase
def pandas_processing_fn(df: pd.DataFrame, **args) -> Iterable[Dict[str,
bytes]]:
""" Parameters:
-----------
df : pandas.DataFrame: DataFrame that must be processed.
**args : key phrase arguments Further arguments to be handed to the
'process_some_data' perform throughout processing.
Returns:
--------
iterable obj
"""
hf_dataset = hf_datasets.Dataset.from_pandas(df=df, break up=args['split'])
tokenizer = AutoTokenizer.from_pretrained(args['tokenizer'])
# we'll implement size, so suppress warnings about sequences too lengthy for the
mannequin
tokenizer.model_max_length = int(1e30)
max_length = args['concat_tokens']
for pattern in hf_dataset:
buffer = []
for pattern in hf_dataset:
encoded = tokenizer(pattern['words'], truncation=False,
padding=False)
iids = encoded['input_ids']
buffer = buffer + iids
whereas len(buffer) >= max_length:
concat_sample = buffer[:max_length]
buffer = []
yield { # convert to bytes to retailer in MDS binary format
'tokens': np.asarray(concat_sample).tobytes()
}After a person’s personal iterator perform is outlined, they will name the identical API by supplying the callable perform, in addition to add additional arguments that the callable perform could require. On this instance, the udf_kwargs comprises the configuration info for the tokenizer. The mds_kwargs is the argument for MDSWriter. The out parameter is the UC Quantity path the place MDS shard recordsdata will likely be saved.
# Empty the MDS output listing
out_path = os.path.be a part of(local_dir, 'mds')
shutil.rmtree(out_path, ignore_errors=True)
# Present a MDS key phrase args. Guarantee `columns` discipline maps the output from
iterable perform (Tokenizer on this instance)
mds_kwargs = {'out': out_path, 'columns': {'tokens': 'bytes'}}
# Tokenizer arguments
udf_kwargs = endoftext
# Convert the dataset to an MDS format. It fetches pattern from dataframe,
tokenize it, and then convert to MDS format.
# It divides the dataframe into 4 components, one components per employee and merge the
`index.json` from 4 sub-parts into one in a guardian listing.
dataframeToMDS(pdf.repartition(4), merge_index=True, mds_kwargs=mds_kwargs,
udf_iterable=pandas_processing_fn, udf_kwargs=udf_kwargs)Customers can instantiate a StreamingDataset class by offering the transformed information (proven above) with the next code, for instant testing.
from torch.utils.information import DataLoader
import streaming
from streaming import StreamingDataset
dataset = StreamingDataset(native=out_path, distant=None)
dataloader = DataLoader(dataset)
for i, information in enumerate(dataloader):
print(information)
#Show solely first 10 batches for demonstration purpsoe
if i == 10:
break By following these steps, customers can seamlessly convert Spark information frames into the StreamingDataset MDS format, enabling environment friendly information processing and evaluation for numerous machine studying and information science duties.
Streaming Knowledge from UC Quantity to MosaicML Platform
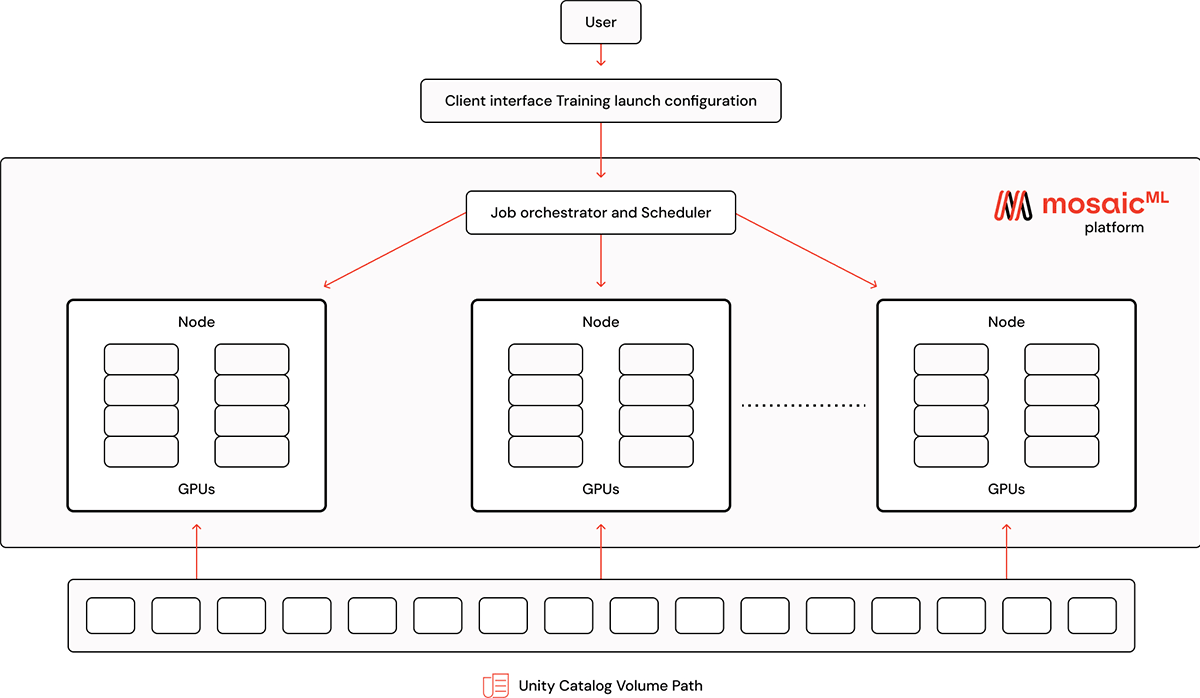
Now that our MDS recordsdata are saved within the UC Quantity, we are able to use the dataset to coach fashions on the MosaicML platform. To configure a coaching run, merely level a distant dataset to the UC Quantity utilizing the dbfs URI with the prefix dbfs:/Volumes
train_loader:
title: uc_dataset
dataset:
native: /my/native/cache
distant: dbfs:/Volumes/<catalog-name>/<schema-name>/<volume-name>/pathThe quantity path ought to level to the listing the place the index.json file lives. This fashion, when fetching coaching information, MosaicML’s platform can pull particular person pattern recordsdata from the listing.
In addition to UC Volumes, the platform will be configured to stream information from DBFS utilizing the identical dbfs URI with the prefix as dbfs:
Credential Setup
Earlier than beginning to prepare on the MosaicML platform, it is necessary to configure authentication for the Databricks shopper. The best method to do that is utilizing a Private Entry Token (PAT). For info on what a PAT is and methods to create one, please see our documentation on authentication.
As soon as the PAT is created, the beneath MosaicML CLI instructions are used to set the DATABRICKS_HOST and DATABRICKS_TOKEN setting variables. They need to correspond to the workspace with entry to the UC Quantity that comprises the MDS datasets.
# Set up MosaicML CLI
pip set up mosaicml-cli
# set the Databricks credentials throughout the MCloud setting
mcli create secret databricksSee MosaicML CLI documentation on secrets and techniques for extra info.
LLM Coaching
As soon as the above credentials are set, the MosaicML platform is able to launch an LLM coaching job with information streaming from UC Quantity. The MosaicML LLM Foundry comprises code for coaching an LLM mannequin utilizing Composer, Streaming dataset, and the MosaicML platform. For demonstration functions, we’re utilizing the mpt-125m.yaml with a tokenized Wikipedia dataset generated by dataframeToMDS API and materialized within the UC Quantity path. Under is the pattern MosaicML platform yaml:
### mpt-125m-uc-volume.yaml ###
integrations:
- integration_type: git_repo
git_repo: mosaicml/llm-foundry
git_branch: v0.3.0
pip_install: -e .[gpu]
picture: mosaicml/pytorch:1.13.1_cu117-python3.10-ubuntu20.04
command: |
# Set up the databricks python sdk
pip set up 'mosaicml-streaming[databricks]>=0.6,<0.7'
cd llm-foundry/scripts
composer prepare/prepare.py prepare/yamls/pretrain/mpt-125m.yaml
data_remote=dbfs:/Volumes/<catalog-name>/<schema-name>/<volume-name>/path
max_duration=1000ba
run_name: mpt-125m-uc-volume
gpu_num: 8
gpu_type: a100_80gb
cluster: # Compute cluster titleAn MCLI job template specifies a run title, a Docker picture, a set of instructions, and a compute cluster to run on.
Customers can run the yaml on MosaicML platform utilizing the command as follows:
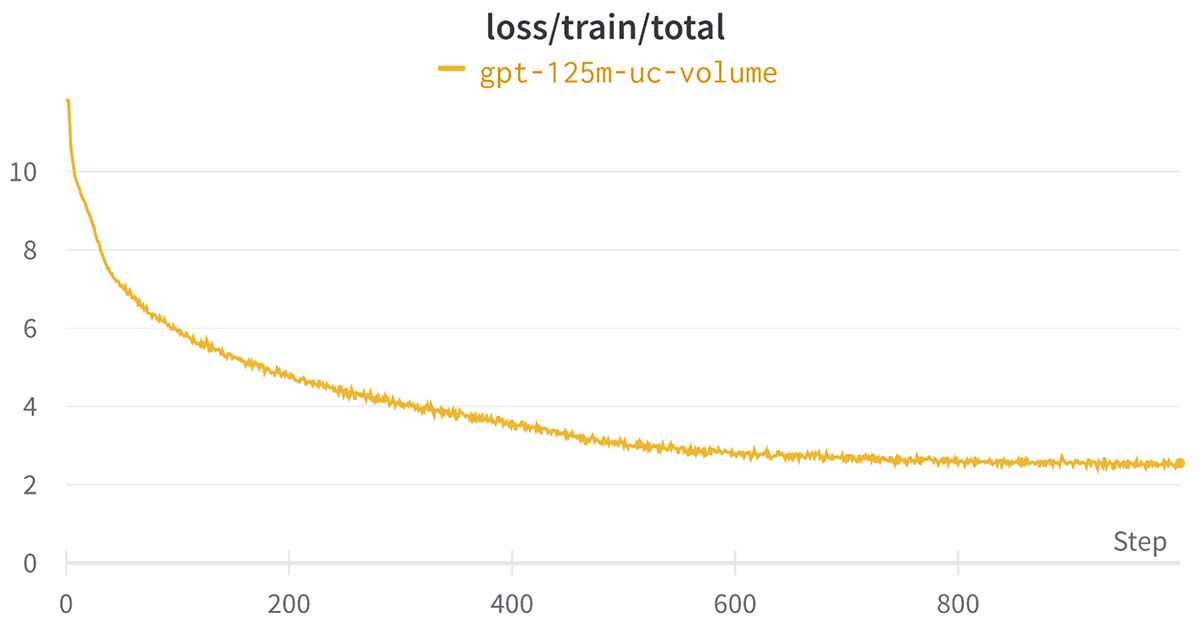
$ mcli run -f mpt-125m-uc-quantity.yaml --followUnder is the loss curve for the above job which exhibits a discount within the loss as anticipated.
What’s Subsequent
On this weblog submit, we have taken step one towards changing the info set to MDS in parallel throughout a number of staff and streaming information straight from the UC Quantity. Subsequent, we plan to enhance the person expertise of LLM coaching when information processing and streaming datasets straight from different information codecs. Keep tuned for extra updates! If you happen to like MosaicML Streaming, give us a star on GitHub. Additionally, be happy to ship us suggestions by means of our Neighborhood Slack or by opening an problem on GitHub.
- Streaming dataset format documentation web page.
- Dataset conversion to MDS format information.
[ad_2]