
[ad_1]
On this period of huge knowledge, organizations worldwide are continually looking for revolutionary methods to extract worth and insights from their huge datasets. Apache Spark presents the scalability and pace wanted to course of massive quantities of knowledge effectively.
Amazon EMR is the industry-leading cloud huge knowledge answer for petabyte-scale knowledge processing, interactive analytics, and machine studying (ML) utilizing open supply frameworks reminiscent of Apache Spark, Apache Hive, and Presto. Amazon EMR is the perfect place to run Apache Spark. You possibly can rapidly and effortlessly create managed Spark clusters from the AWS Administration Console, AWS Command Line Interface (AWS CLI), or Amazon EMR API. You may as well use extra Amazon EMR options, together with quick Amazon Easy Storage Service (Amazon S3) connectivity utilizing the Amazon EMR File System (EMRFS), integration with the Amazon EC2 Spot market and the AWS Glue Knowledge Catalog, and EMR Managed Scaling so as to add or take away situations out of your cluster. Amazon EMR Studio is an built-in growth setting (IDE) that makes it easy for knowledge scientists and knowledge engineers to develop, visualize, and debug knowledge engineering and knowledge science functions written in R, Python, Scala, and PySpark. EMR Studio gives totally managed Jupyter notebooks, and instruments like Spark UI and YARN Timeline Service to simplify debugging.
To unlock the potential hidden inside the knowledge troves, it’s important to transcend conventional analytics. Enter generative AI, a cutting-edge expertise that mixes ML with creativity to generate human-like textual content, artwork, and even code. Amazon Bedrock is essentially the most easy approach to construct and scale generative AI functions with basis fashions (FMs). Amazon Bedrock is a totally managed service that makes FMs from Amazon and main AI corporations out there by an API, so you possibly can rapidly experiment with quite a lot of FMs within the playground, and use a single API for inference whatever the fashions you select, providing you with the flexibleness to make use of FMs from completely different suppliers and maintain updated with the newest mannequin variations with minimal code adjustments.
On this submit, we discover how one can supercharge your knowledge analytics with generative AI utilizing Amazon EMR, Amazon Bedrock, and the pyspark-ai library. The pyspark-ai library is an English SDK for Apache Spark. It takes directions in English language and compiles them into PySpark objects like DataFrames. This makes it easy to work with Spark, permitting you to give attention to extracting worth out of your knowledge.
Resolution overview
The next diagram illustrates the structure for utilizing generative AI with Amazon EMR and Amazon Bedrock.
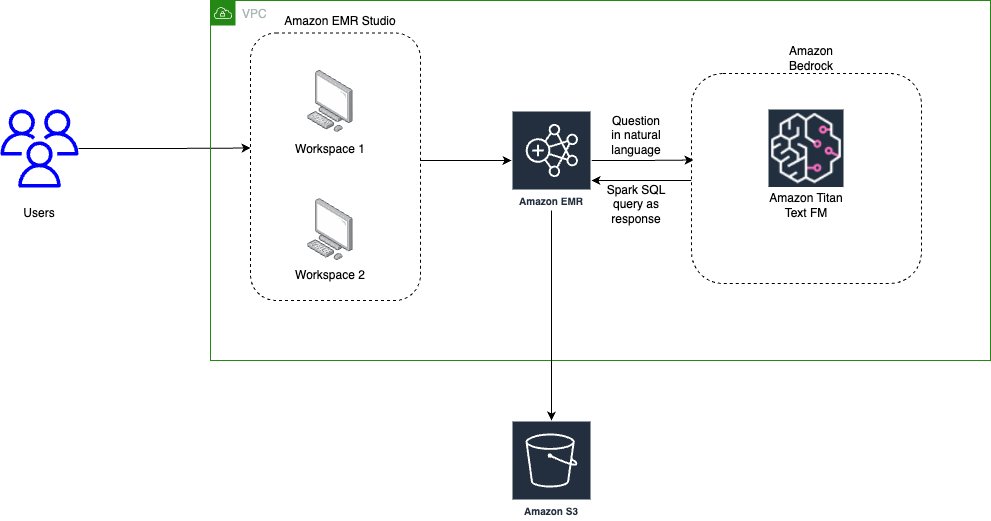
EMR Studio is a web-based IDE for totally managed Jupyter notebooks that run on EMR clusters. We work together with EMR Studio Workspaces related to a working EMR cluster and run the pocket book supplied as a part of this submit. We use the New York Metropolis Taxi knowledge to garner insights into varied taxi rides taken by customers. We ask the questions in pure language on high of the info loaded in Spark DataFrame. The pyspark-ai library then makes use of the Amazon Titan Textual content FM from Amazon Bedrock to create a SQL question primarily based on the pure language query. The pyspark-ai library takes the SQL question, runs it utilizing Spark SQL, and gives outcomes again to the person.
On this answer, you possibly can create and configure the required assets in your AWS account with an AWS CloudFormation template. The template creates the AWS Glue database and tables, S3 bucket, VPC, and different AWS Id and Entry Administration (IAM) assets which are used within the answer.
The template is designed to show learn how to use EMR Studio with the pyspark-ai bundle and Amazon Bedrock, and isn’t meant for manufacturing use with out modification. Moreover, the template makes use of the us-east-1 Area and will not work in different Areas with out modification. The template creates assets that incur prices whereas they’re in use. Comply with the cleanup steps on the finish of this submit to delete the assets and keep away from pointless expenses.
Conditions
Earlier than you launch the CloudFormation stack, guarantee you’ve got the next:
- An AWS account that gives entry to AWS companies
- An IAM person with an entry key and secret key to configure the AWS CLI, and permissions to create an IAM position, IAM insurance policies, and stacks in AWS CloudFormation
- The Titan Textual content G1 – Specific mannequin is at present in preview, so it’s good to have preview entry to make use of it as a part of this submit
Create assets with AWS CloudFormation
The CloudFormation creates the next AWS assets:
- A VPC stack with non-public and public subnets to make use of with EMR Studio, route tables, and NAT gateway.
- An EMR cluster with Python 3.9 put in. We’re utilizing a bootstrap motion to put in Python 3.9 and different related packages like pyspark-ai and Amazon Bedrock dependencies. (For extra data, consult with the bootstrap script.)
- An S3 bucket for the EMR Studio Workspace and pocket book storage.
- IAM roles and insurance policies for EMR Studio setup, Amazon Bedrock entry, and working notebooks
To get began, full the next steps:
- Select Launch Stack:

- Choose I acknowledge that this template could create IAM assets.
The CloudFormation stack takes roughly 20–half-hour to finish. You possibly can monitor its progress on the AWS CloudFormation console. When its standing reads CREATE_COMPLETE, your AWS account may have the assets essential to implement this answer.
Create EMR Studio
Now you possibly can create an EMR Studio and Workspace to work with the pocket book code. Full the next steps:
- On the EMR Studio console, select Create Studio.
- Enter the Studio Title as
GenAI-EMR-Studioand supply an outline. - Within the Networking and safety part, specify the next:
- For VPC, select the VPC you created as a part of the CloudFormation stack that you just deployed. Get the VPC ID utilizing the CloudFormation outputs for the VPCID key.
- For Subnets, select all 4 subnets.
- For Safety and entry, choose Customized safety group.
- For Cluster/endpoint safety group, select
EMRSparkAI-Cluster-Endpoint-SG. - For Workspace safety group, select
EMRSparkAI-Workspace-SG.
- Within the Studio service position part, specify the next:
- For Authentication, choose AWS Id and Entry Administration (IAM).
- For AWS IAM service position, select
EMRSparkAI-StudioServiceRole.
- Within the Workspace storage part, browse and select the S3 bucket for storage beginning with
emr-sparkai-<account-id>. - Select Create Studio.

- When the EMR Studio is created, select the hyperlink below Studio Entry URL to entry the Studio.

- While you’re within the Studio, select Create workspace.
- Add
emr-genaibecause the title for the Workspace and select Create workspace. - When the Workspace is created, select its title to launch the Workspace (be sure to’ve disabled any pop-up blockers).

Huge knowledge analytics utilizing Apache Spark with Amazon EMR and generative AI
Now that we’ve got accomplished the required setup, we will begin performing huge knowledge analytics utilizing Apache Spark with Amazon EMR and generative AI.
As a primary step, we load a pocket book that has the required code and examples to work with the use case. We use NY Taxi dataset, which comprises particulars about taxi rides.
- Obtain the pocket book file NYTaxi.ipynb and add it to your Workspace by selecting the add icon.

- After the pocket book is imported, open the pocket book and select
PySparkbecause the kernel.
PySpark AI by default makes use of OpenAI’s ChatGPT4.0 because the LLM mannequin, however you can even plug in fashions from Amazon Bedrock, Amazon SageMaker JumpStart, and different third-party fashions. For this submit, we present learn how to combine the Amazon Bedrock Titan mannequin for SQL question technology and run it with Apache Spark in Amazon EMR.
- To get began with the pocket book, it’s good to affiliate the Workspace to a compute layer. To take action, select the Compute icon within the navigation pane and select the EMR cluster created by the CloudFormation stack.

- Configure the Python parameters to make use of the up to date Python 3.9 bundle with Amazon EMR:
- Import the mandatory libraries:
- After the libraries are imported, you possibly can outline the LLM mannequin from Amazon Bedrock. On this case, we use amazon.titan-text-express-v1. That you must enter the Area and Amazon Bedrock endpoint URL primarily based in your preview entry for the Titan Textual content G1 – Specific mannequin.
- Join Spark AI to the Amazon Bedrock LLM mannequin for SQL question technology primarily based on questions in pure language:
Right here, we’ve got initialized Spark AI with verbose=False; you can even set verbose=True to see extra particulars.
Now you possibly can learn the NYC Taxi knowledge in a Spark DataFrame and use the facility of generative AI in Spark.
- For instance, you possibly can ask the depend of the variety of data within the dataset:
We get the next response:
Spark AI internally makes use of LangChain and SQL chain, which cover the complexity from end-users working with queries in Spark.
The pocket book has just a few extra instance eventualities to discover the facility of generative AI with Apache Spark and Amazon EMR.
Clear up
Empty the contents of the S3 bucket emr-sparkai-<account-id>, delete the EMR Studio Workspace created as a part of this submit, after which delete the CloudFormation stack that you just deployed.
Conclusion
This submit confirmed how one can supercharge your huge knowledge analytics with the assistance of Apache Spark with Amazon EMR and Amazon Bedrock. The PySpark AI bundle permits you to derive significant insights out of your knowledge. It helps cut back growth and evaluation time, decreasing time to jot down handbook queries and permitting you to give attention to your small business use case.
In regards to the Authors
 Saurabh Bhutyani is a Principal Analytics Specialist Options Architect at AWS. He’s obsessed with new applied sciences. He joined AWS in 2019 and works with clients to supply architectural steerage for working generative AI use instances, scalable analytics options and knowledge mesh architectures utilizing AWS companies like Amazon Bedrock, Amazon SageMaker, Amazon EMR, Amazon Athena, AWS Glue, AWS Lake Formation, and Amazon DataZone.
Saurabh Bhutyani is a Principal Analytics Specialist Options Architect at AWS. He’s obsessed with new applied sciences. He joined AWS in 2019 and works with clients to supply architectural steerage for working generative AI use instances, scalable analytics options and knowledge mesh architectures utilizing AWS companies like Amazon Bedrock, Amazon SageMaker, Amazon EMR, Amazon Athena, AWS Glue, AWS Lake Formation, and Amazon DataZone.
 Harsh Vardhan is an AWS Senior Options Architect, specializing in analytics. He has over 8 years of expertise working within the area of huge knowledge and knowledge science. He’s obsessed with serving to clients undertake finest practices and uncover insights from their knowledge.
Harsh Vardhan is an AWS Senior Options Architect, specializing in analytics. He has over 8 years of expertise working within the area of huge knowledge and knowledge science. He’s obsessed with serving to clients undertake finest practices and uncover insights from their knowledge.
[ad_2]