
[ad_1]
Unstructured information is info that doesn’t conform to a predefined schema or isn’t organized based on a preset information mannequin. Unstructured info might have a bit of or loads of construction however in methods which are surprising or inconsistent. Textual content, photos, audio, and movies are frequent examples of unstructured information. Most corporations produce and eat unstructured information reminiscent of paperwork, emails, net pages, engagement middle telephone calls, and social media. By some estimates, unstructured information could make as much as 80–90% of all new enterprise information and is rising many instances quicker than structured information. After a long time of digitizing every part in your enterprise, you might have an infinite quantity of knowledge, however with dormant worth. Nevertheless, with the assistance of AI and machine studying (ML), new software program instruments at the moment are obtainable to unearth the worth of unstructured information.
On this put up, we talk about how AWS can assist you efficiently deal with the challenges of extracting insights from unstructured information. We talk about varied design patterns and architectures for extracting and cataloging helpful insights from unstructured information utilizing AWS. Moreover, we present find out how to use AWS AI/ML companies for analyzing unstructured information.
Why it’s difficult to course of and handle unstructured information
Unstructured information makes up a big proportion of the information within the enterprise that may’t be saved in a conventional relational database administration techniques (RDBMS). Understanding the information, categorizing it, storing it, and extracting insights from it may be difficult. As well as, figuring out incremental modifications requires specialised patterns and detecting delicate information and assembly compliance necessities calls for stylish features. It may be troublesome to combine unstructured information with structured information from present info techniques. Some view structured and unstructured information as apples and oranges, as a substitute of being complementary. However most necessary of all, the assumed dormant worth within the unstructured information is a query mark, which may solely be answered after these subtle methods have been utilized. Due to this fact, there’s a have to with the ability to analyze and extract worth from the information economically and flexibly.
Resolution overview
Information and metadata discovery is without doubt one of the major necessities in information analytics, the place information shoppers discover what information is on the market and in what format, after which eat or question it for evaluation. For those who can apply a schema on high of the dataset, then it’s simple to question as a result of you possibly can load the information right into a database or impose a digital desk schema for querying. However within the case of unstructured information, metadata discovery is difficult as a result of the uncooked information isn’t simply readable.
You possibly can combine totally different applied sciences or instruments to construct an answer. On this put up, we clarify find out how to combine totally different AWS companies to supply an end-to-end resolution that features information extraction, administration, and governance.
The answer integrates information in three tiers. The primary is the uncooked enter information that will get ingested by supply techniques, the second is the output information that will get extracted from enter information utilizing AI, and the third is the metadata layer that maintains a relationship between them for information discovery.
The next is a high-level structure of the answer we will construct to course of the unstructured information, assuming the enter information is being ingested to the uncooked enter object retailer.
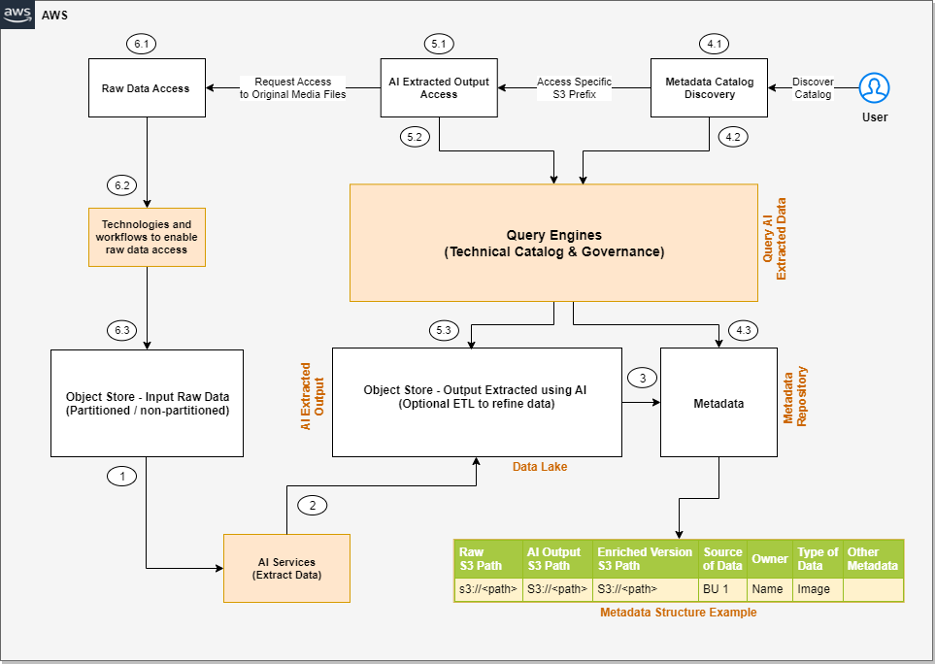
The steps of the workflow are as follows:
- Built-in AI companies extract information from the unstructured information.
- These companies write the output to an information lake.
- A metadata layer helps construct the connection between the uncooked information and AI extracted output. When the information and metadata can be found for end-users, we will break the consumer entry sample into further steps.
- Within the metadata catalog discovery step, we will use question engines to entry the metadata for discovery and apply filters as per our analytics wants. Then we transfer to the following stage of accessing the precise information extracted from the uncooked unstructured information.
- The tip-user accesses the output of the AI companies and makes use of the question engines to question the structured information obtainable within the information lake. We are able to optionally combine further instruments that assist management entry and supply governance.
- There is likely to be eventualities the place, after accessing the AI extracted output, the end-user desires to entry the unique uncooked object (reminiscent of media information) for additional evaluation. Moreover, we’d like to ensure we have now entry management insurance policies so the end-user has entry solely to the respective uncooked information they wish to entry.
Now that we perceive the high-level structure, let’s talk about what AWS companies we will combine in every step of the structure to supply an end-to-end resolution.
The next diagram is the improved model of our resolution structure, the place we have now built-in AWS companies.

Let’s perceive how these AWS companies are built-in intimately. We have now divided the steps into two broad consumer flows: information processing and metadata enrichment (Steps 1–3) and end-users accessing the information and metadata with fine-grained entry management (Steps 4–6).
- Numerous AI companies (which we talk about within the subsequent part) extract information from the unstructured datasets.
- The output is written to an Amazon Easy Storage Service (Amazon S3) bucket (labeled Extracted JSON within the previous diagram). Optionally, we will restructure the enter uncooked objects for higher partitioning, which can assist whereas implementing fine-grained entry management on the uncooked enter information (labeled because the Partitioned bucket within the diagram).
- After the preliminary information extraction part, we will apply further transformations to complement the datasets utilizing AWS Glue. We additionally construct a further metadata layer, which maintains a relationship between the uncooked S3 object path, the AI extracted output path, the optionally available enriched model S3 path, and every other metadata that can assist the end-user uncover the information.
- Within the metadata catalog discovery step, we use the AWS Glue Information Catalog because the technical catalog, Amazon Athena and Amazon Redshift Spectrum as question engines, AWS Lake Formation for fine-grained entry management, and Amazon DataZone for extra governance.
- The AI extracted output is anticipated to be obtainable as a delimited file or in JSON format. We are able to create an AWS Glue Information Catalog desk for querying utilizing Athena or Redshift Spectrum. Just like the earlier step, we will use Lake Formation insurance policies for fine-grained entry management.
- Lastly, the end-user accesses the uncooked unstructured information obtainable in Amazon S3 for additional evaluation. We have now proposed integrating Amazon S3 Entry Factors for entry management at this layer. We clarify this intimately later on this put up.
Now let’s develop the next elements of the structure to grasp the implementation higher:
- Utilizing AWS AI companies to course of unstructured information
- Utilizing S3 Entry Factors to combine entry management on uncooked S3 unstructured information
Course of unstructured information with AWS AI companies
As we mentioned earlier, unstructured information can are available in quite a lot of codecs, reminiscent of textual content, audio, video, and pictures, and every sort of knowledge requires a special method for extracting metadata. AWS AI companies are designed to extract metadata from several types of unstructured information. The next are probably the most generally used companies for unstructured information processing:
- Amazon Comprehend – This pure language processing (NLP) service makes use of ML to extract metadata from textual content information. It could analyze textual content in a number of languages, detect entities, extract key phrases, decide sentiment, and extra. With Amazon Comprehend, you possibly can simply achieve insights from massive volumes of textual content information reminiscent of extracting product entity, buyer title, and sentiment from social media posts.
- Amazon Transcribe – This speech-to-text service makes use of ML to transform speech to textual content and extract metadata from audio information. It could acknowledge a number of audio system, transcribe conversations, establish key phrases, and extra. With Amazon Transcribe, you possibly can convert unstructured information reminiscent of buyer help recordings into textual content and additional derive insights from it.
- Amazon Rekognition – This picture and video evaluation service makes use of ML to extract metadata from visible information. It could acknowledge objects, individuals, faces, and textual content, detect inappropriate content material, and extra. With Amazon Rekognition, you possibly can simply analyze photos and movies to achieve insights reminiscent of figuring out entity sort (human or different) and figuring out if the individual is a identified superstar in a picture.
- Amazon Textract – You should use this ML service to extract metadata from scanned paperwork and pictures. It could extract textual content, tables, and varieties from photos, PDFs, and scanned paperwork. With Amazon Textract, you possibly can digitize paperwork and extract information reminiscent of buyer title, product title, product worth, and date from an bill.
- Amazon SageMaker – This service lets you construct and deploy customized ML fashions for a variety of use circumstances, together with extracting metadata from unstructured information. With SageMaker, you possibly can construct customized fashions which are tailor-made to your particular wants, which could be significantly helpful for extracting metadata from unstructured information that requires a excessive diploma of accuracy or domain-specific information.
- Amazon Bedrock – This absolutely managed service affords a alternative of high-performing basis fashions (FMs) from main AI corporations like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon with a single API. It additionally affords a broad set of capabilities to construct generative AI functions, simplifying growth whereas sustaining privateness and safety.
With these specialised AI companies, you possibly can effectively extract metadata from unstructured information and use it for additional evaluation and insights. It’s necessary to notice that every service has its personal strengths and limitations, and choosing the proper service on your particular use case is important for attaining correct and dependable outcomes.
AWS AI companies can be found through varied APIs, which lets you combine AI capabilities into your functions and workflows. AWS Step Capabilities is a serverless workflow service that permits you to coordinate and orchestrate a number of AWS companies, together with AI companies, right into a single workflow. This may be significantly helpful when you might want to course of massive quantities of unstructured information and carry out a number of AI-related duties, reminiscent of textual content evaluation, picture recognition, and NLP.
With Step Capabilities and AWS Lambda features, you possibly can create subtle workflows that embrace AI companies and different AWS companies. For example, you should use Amazon S3 to retailer enter information, invoke a Lambda perform to set off an Amazon Transcribe job to transcribe an audio file, and use the output to set off an Amazon Comprehend evaluation job to generate sentiment metadata for the transcribed textual content. This lets you create complicated, multi-step workflows which are simple to handle, scalable, and cost-effective.
The next is an instance structure that reveals how Step Capabilities can assist invoke AWS AI companies utilizing Lambda features.
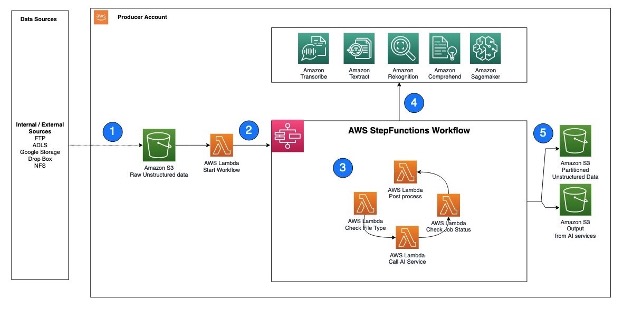
The workflow steps are as follows:
- Unstructured information, reminiscent of textual content information, audio information, and video information, are ingested into the S3 uncooked bucket.
- A Lambda perform is triggered to learn the information from the S3 bucket and name Step Capabilities to orchestrate the workflow required to extract the metadata.
- The Step Capabilities workflow checks the kind of file, calls the corresponding AWS AI service APIs, checks the job standing, and performs any postprocessing required on the output.
- AWS AI companies could be accessed through APIs and invoked as batch jobs. To extract metadata from several types of unstructured information, you should use a number of AI companies in sequence, with every service processing the corresponding file sort.
- After the Step Capabilities workflow completes the metadata extraction course of and performs any required postprocessing, the ensuing output is saved in an S3 bucket for cataloging.
Subsequent, let’s perceive how can we implement safety or entry management on each the extracted output in addition to the uncooked enter objects.
Implement entry management on uncooked and processed information in Amazon S3
We simply contemplate entry controls for 3 varieties of information when managing unstructured information: the AI-extracted semi-structured output, the metadata, and the uncooked unstructured unique information. In relation to AI extracted output, it’s in JSON format and could be restricted through Lake Formation and Amazon DataZone. We suggest holding the metadata (info that captures which unstructured datasets are already processed by the pipeline and obtainable for evaluation) open to your group, which can allow metadata discovery throughout the group.
To manage entry of uncooked unstructured information, you possibly can combine S3 Entry Factors and discover further help sooner or later as AWS companies evolve. S3 Entry Factors simplify information entry for any AWS service or buyer utility that shops information in Amazon S3. Entry factors are named community endpoints which are hooked up to buckets that you should use to carry out S3 object operations. Every entry level has distinct permissions and community controls that Amazon S3 applies for any request that’s made by that entry level. Every entry level enforces a personalized entry level coverage that works at the side of the bucket coverage that’s hooked up to the underlying bucket. With S3 Entry Factors, you possibly can create distinctive entry management insurance policies for every entry level to simply management entry to particular datasets inside an S3 bucket. This works effectively in multi-tenant or shared bucket eventualities the place customers or groups are assigned to distinctive prefixes inside one S3 bucket.
An entry level can help a single consumer or utility, or teams of customers or functions inside and throughout accounts, permitting separate administration of every entry level. Each entry level is related to a single bucket and incorporates a community origin management and a Block Public Entry management. For instance, you possibly can create an entry level with a community origin management that solely permits storage entry out of your digital personal cloud (VPC), a logically remoted part of the AWS Cloud. You may also create an entry level with the entry level coverage configured to solely permit entry to things with an outlined prefix or to things with particular tags. You may also configure customized Block Public Entry settings for every entry level.
The next structure gives an summary of how an end-user can get entry to particular S3 objects by assuming a particular AWS Id and Entry Administration (IAM) function. When you have a lot of S3 objects to manage entry, contemplate grouping the S3 objects, assigning them tags, after which defining entry management by tags.
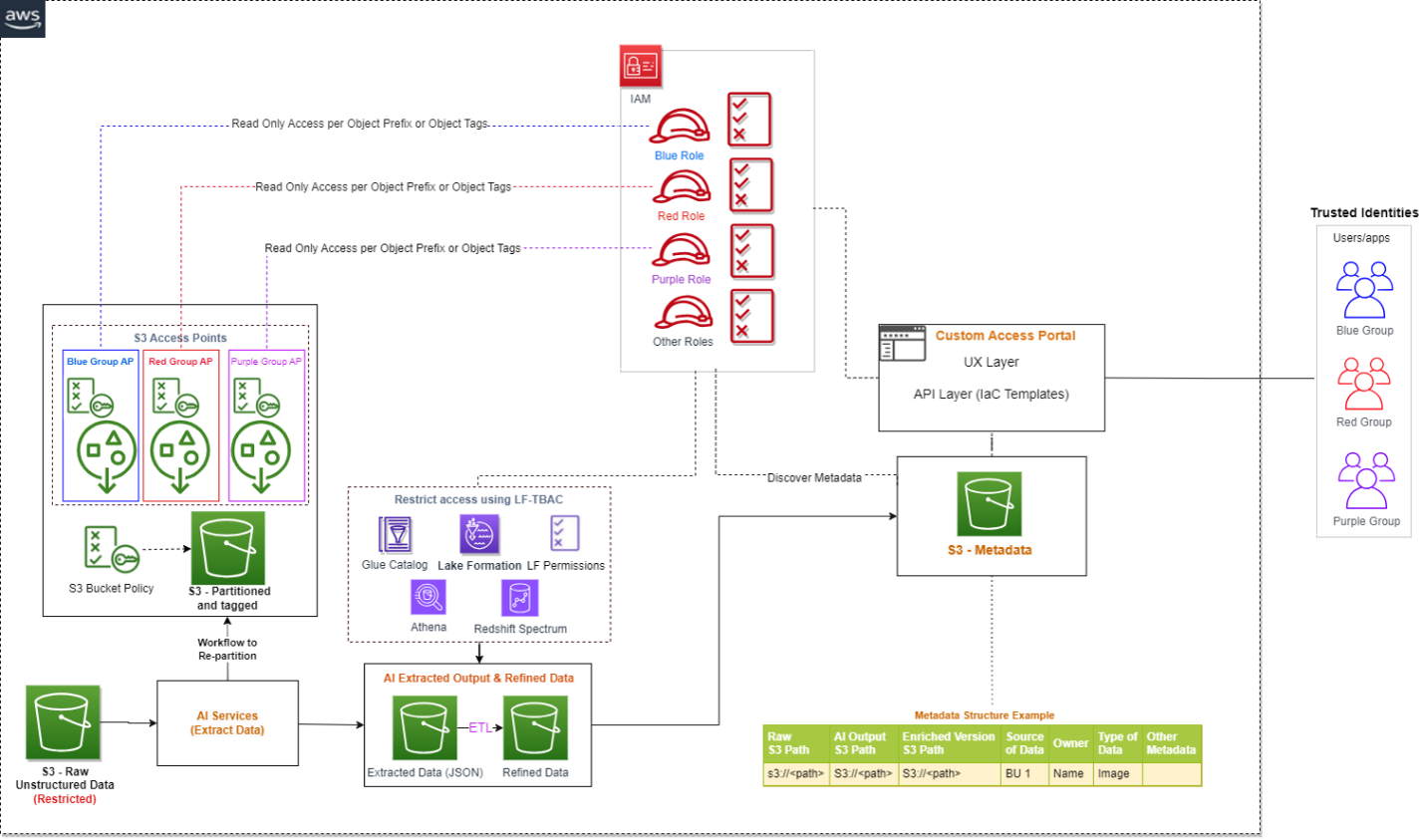
In case you are implementing an answer that integrates S3 information obtainable in a number of AWS accounts, you possibly can reap the benefits of cross-account help for S3 Entry Factors.
Conclusion
This put up defined how you should use AWS AI companies to extract readable information from unstructured datasets, construct a metadata layer on high of them to permit information discovery, and construct an entry management mechanism on high of the uncooked S3 objects and extracted information utilizing Lake Formation, Amazon DataZone, and S3 Entry Factors.
Along with AWS AI companies, you can even combine massive language fashions with vector databases to allow semantic or similarity search on high of unstructured datasets. To study extra about find out how to allow semantic search on unstructured information by integrating Amazon OpenSearch Service as a vector database, check with Attempt semantic search with the Amazon OpenSearch Service vector engine.
As of penning this put up, S3 Entry Factors is without doubt one of the finest options to implement entry management on uncooked S3 objects utilizing tagging, however as AWS service options evolve sooner or later, you possibly can discover various choices as effectively.
Concerning the Authors
 Sakti Mishra is a Principal Options Architect at AWS, the place he helps prospects modernize their information structure and outline their end-to-end information technique, together with information safety, accessibility, governance, and extra. He’s additionally the creator of the guide Simplify Large Information Analytics with Amazon EMR. Outdoors of labor, Sakti enjoys studying new applied sciences, watching motion pictures, and visiting locations with household.
Sakti Mishra is a Principal Options Architect at AWS, the place he helps prospects modernize their information structure and outline their end-to-end information technique, together with information safety, accessibility, governance, and extra. He’s additionally the creator of the guide Simplify Large Information Analytics with Amazon EMR. Outdoors of labor, Sakti enjoys studying new applied sciences, watching motion pictures, and visiting locations with household.
 Bhavana Chirumamilla is a Senior Resident Architect at AWS with a robust ardour for information and machine studying operations. She brings a wealth of expertise and enthusiasm to assist enterprises construct efficient information and ML methods. In her spare time, Bhavana enjoys spending time along with her household and interesting in varied actions reminiscent of touring, mountain climbing, gardening, and watching documentaries.
Bhavana Chirumamilla is a Senior Resident Architect at AWS with a robust ardour for information and machine studying operations. She brings a wealth of expertise and enthusiasm to assist enterprises construct efficient information and ML methods. In her spare time, Bhavana enjoys spending time along with her household and interesting in varied actions reminiscent of touring, mountain climbing, gardening, and watching documentaries.
 Sheela Sonone is a Senior Resident Architect at AWS. She helps AWS prospects make knowledgeable decisions and trade-offs about accelerating their information, analytics, and AI/ML workloads and implementations. In her spare time, she enjoys spending time along with her household—normally on tennis courts.
Sheela Sonone is a Senior Resident Architect at AWS. She helps AWS prospects make knowledgeable decisions and trade-offs about accelerating their information, analytics, and AI/ML workloads and implementations. In her spare time, she enjoys spending time along with her household—normally on tennis courts.
 Daniel Bruno is a Principal Resident Architect at AWS. He had been constructing analytics and machine studying options for over 20 years and splits his time serving to prospects construct information science applications and designing impactful ML merchandise.
Daniel Bruno is a Principal Resident Architect at AWS. He had been constructing analytics and machine studying options for over 20 years and splits his time serving to prospects construct information science applications and designing impactful ML merchandise.
[ad_2]