
[ad_1]
We’re excited to announce the Common Availability of Predictive I/O for updates.
This functionality harnesses Photon and Lakehouse AI so as to considerably velocity up Knowledge Manipulation Language (DML) operations like MERGE, UPDATE and DELETE, with no efficiency modifications to learn queries.
Predictive I/O for updates accomplishes this via an AI mannequin that intelligently applies Deletion Vectors, a Delta Lake functionality, which permits for the monitoring of deleted rows via hyper-optimized bitmap recordsdata. The web result’s considerably quicker queries with considerably much less overhead for knowledge engineering groups.
Shortly following GA, we are going to allow Predictive I/O for updates by default on new tables. To right away opt-in, consult with our documentation or the steps on the very finish of this publish.
Conventional approaches: choose your poison
Historically, there have been two approaches to processing DML queries, every of which had totally different strengths and weaknesses.
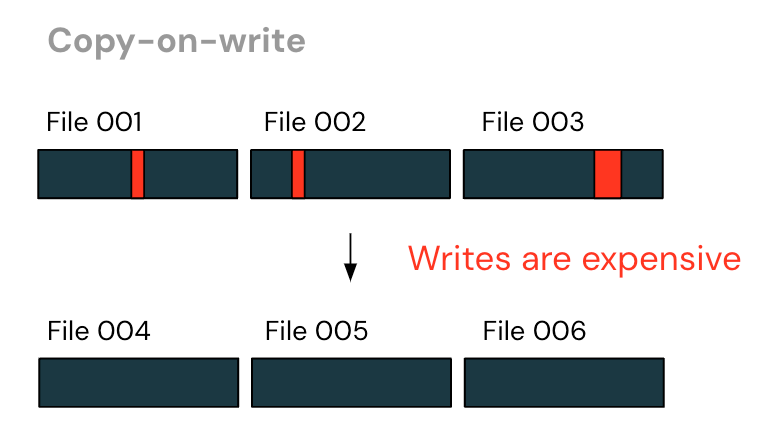
The primary, most typical strategy is “copy-on-write”. Question engines would determine the recordsdata that comprise the rows needing modification, after which rewrite all unmodified rows to a brand new file – filtering out the deleted rows and including up to date ones.
Underneath this strategy, writes might be very costly. It’s common that with DML queries, just a few rows are modified. With copy-on-write, this ends in a rewrite of practically the complete file – although little or no has modified!
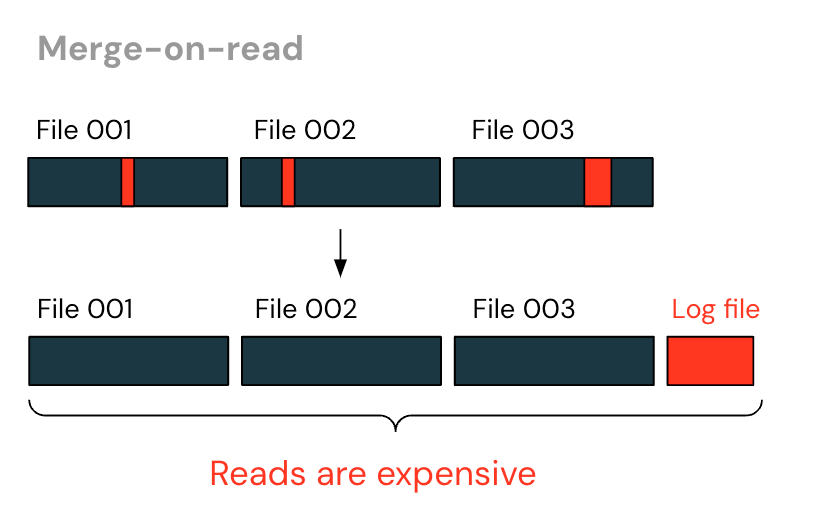
Another strategy is “merge-on-read”. As an alternative of rewriting the complete file, log recordsdata are written that observe rows that had been deleted. The reader then items collectively the desk by studying each the information recordsdata and the extra log recordsdata.
With merge-on-reads, writes are a lot quicker – no extra rewriting unchanged recordsdata. Nevertheless, reads grow to be more and more costly over time as bigger log recordsdata are generated, all of which the reader should piece collectively. The tip consumer additionally has to find out when to “purge” these log recordsdata – rewriting the log recordsdata and knowledge recordsdata into a brand new knowledge file – so as to return to take care of cheap learn efficiency.
The tip consequence: the standard approaches each have their very own strengths and weaknesses, forcing you to “choose your poison”. For every desk, it’s good to ask: is copy-on-write or merge-on-read higher for this use case? And should you went with the latter, how typically must you purge your log recordsdata?
Introducing Predictive I/O for updates – AI supplies the very best of all worlds
Predictive I/O for updates delivers the very best of all worlds – lightning-fast DML operations and nice learn efficiency, all with out the necessity for customers to determine when to “purge” the log recordsdata. That is achieved utilizing an AI mannequin to routinely decide when to use and purge Delta Lake Deletion Vectors.
The tables written by Predictive I/O for updates stay within the open Delta Lake format, readable by the Delta Lake ecosystem of connectors, together with Trino and Spark operating OSS Delta 2.3.0 and above.
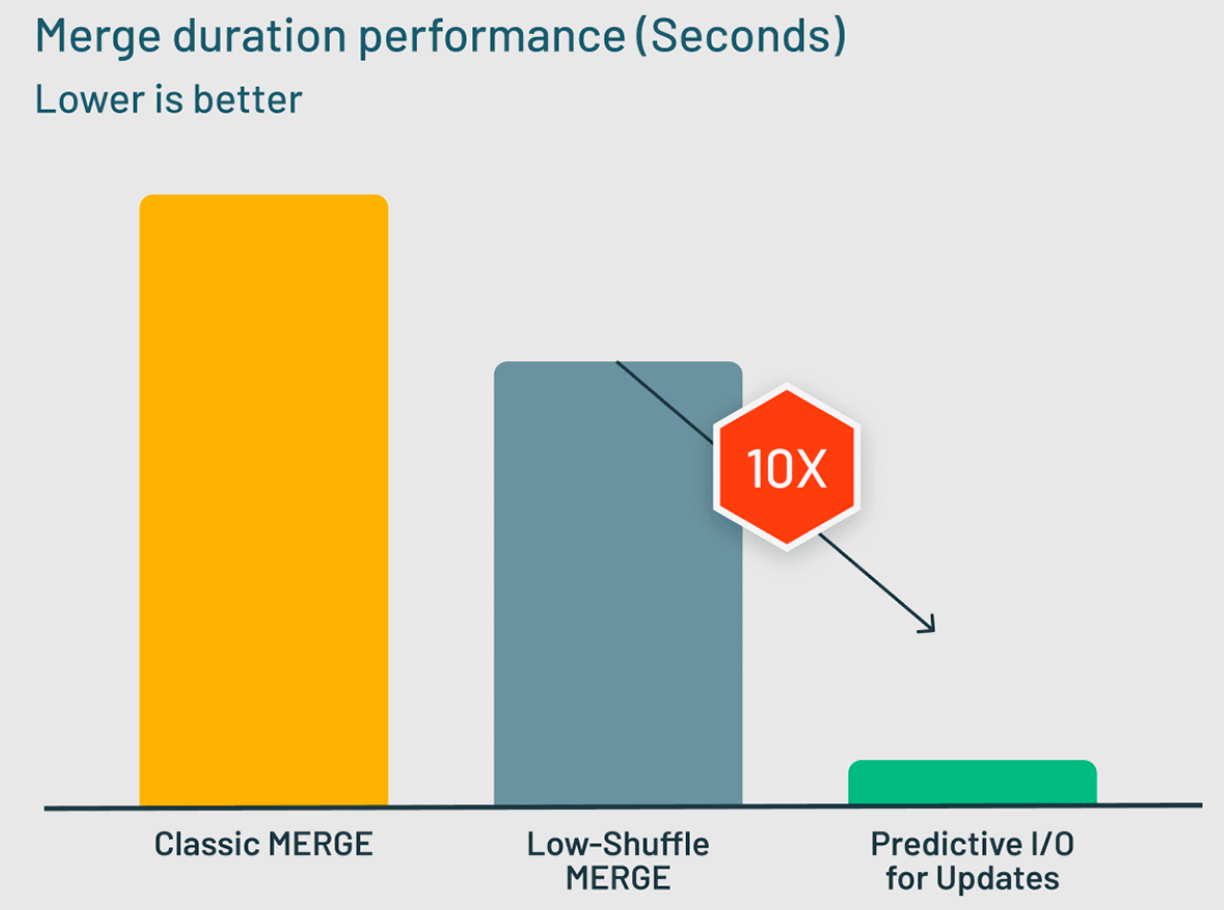
In benchmarks of typical Knowledge Warehousing MERGE workloads, Predictive I/O for updates delivers 10x efficiency enhancements over the Low-Shuffle Merge approach utilized by Photon earlier than.
For the reason that Public Preview of Predictive I/O for updates was introduced in April, we’ve labored with a whole bunch of consumers who’ve efficiently used the aptitude to get large efficiency positive aspects on their DML queries.
Throughout that point, Predictive I/O for updates has written many billions of Deletion Vectors, and we’ve used that knowledge to additional refine the AI fashions that are used to find out when finest to use Deletion Vectors. We’ve discovered that in complete, Deletion Vectors have prevented the unnecessary rewrites of over 15 trillion rows, which might’ve in any other case been written beneath copy-on-write approaches. It’s no marvel that clients reported important speedups on their DML workloads:
“Predictive I/O for updates has helped us considerably velocity up our DML operations, decreasing compute prices and accelerating time-to-insight. We’re comfortable that this functionality has been set-and-forget, releasing up our time to concentrate on getting enterprise worth from our knowledge.” — Antonio del Rio, Knowledge Engineering, Avoristech
Coming quickly: Predictive I/O for updates enabled proper out of the field for newly created tables
The promising outcomes from Public Preview have given us the arrogance not solely to take the aptitude to Common Availability but additionally to start enabling Predictive I/O by default for newly created tables. These modifications can even apply to enabling Deletion Vectors even for clusters with out Photon enabled – which ought to nonetheless see a efficiency enhance (although smaller in magnitude than Predictive I/O for updates).
This enchancment will enable you to get efficiency enhancements proper out of the field with no need to recollect to set the related desk properties.
You may allow Predictive I/O for updates throughout your workloads via a brand new workspace setting. This setting is on the market now on Azure and AWS, and will probably be obtainable in GCP coming quickly. To entry it:
- As a workspace admin, go to Admin Settings for the workspace
- Choose the Workspace settings tab
- Go to the setting titled Auto-Allow Deletion Vectors
This setting takes impact for all Databricks SQL Warehouses and clusters with Databricks runtime 14.0+.
Alternatively, this similar setting can be utilized to decide out of enablement by default, by merely setting the setting to Disabled.
Allow Predictive I/O right this moment to carry the facility of AI to supercharge your DML queries! And look out for extra AI-powered Databricks capabilities quickly to come back.
[ad_2]