
[ad_1]

Cloudera SQL Stream Builder (SSB) provides the facility of a unified stream processing engine to non-technical customers to allow them to combine, combination, question, and analyze each streaming and batch knowledge sources in a single SQL interface. This enables enterprise customers to outline occasions of curiosity for which they should constantly monitor and reply rapidly.
There are a lot of methods to distribute the outcomes of SSB’s steady queries to embed actionable insights into enterprise processes. On this weblog we’ll cowl materialized views—a particular kind of sink that makes the output accessible through REST API.
In SSB we are able to use SQL to question stream or batch knowledge, carry out some form of aggregation or knowledge manipulation, then output the end result right into a sink. A sink could possibly be one other knowledge stream or we might use a particular kind of information sink we name a materialized view (MV). An MV is a particular kind of sink that permits us to output knowledge from our question right into a tabular format endured in a PostgreSQL database. We will additionally question this knowledge later, optionally with filters utilizing SSBs REST API.
If we need to simply use the outcomes of our SQL job from an exterior utility, MVs are the most effective and simplest way to take action. All we have to do is outline the MV on the UI interface and functions will be capable of retrieve knowledge through REST API.
Think about, as an illustration, that we have now a real-time Kafka stream containing airplane knowledge and we’re engaged on an utility that should obtain all planes in a sure space, above some altitude at any given time through REST. This isn’t a easy job to do, since planes are always shifting and altering their altitudes, and we have to learn this knowledge from an unbounded stream. If we add a materialized view to our SSB job, that may create a REST endpoint from which we can retrieve the newest end result from our job. We will additionally add filters to this request, so for instance, our utility can use the MV to point out all of the planes which might be flying larger than some user-specified altitude.
Creating a brand new job
An MV at all times belongs to a single job, so to create an MV we should first create a job in SSB. To create a job we may even have to create a undertaking first which can present us a Software program Improvement Lifecycle (SDLC) for our functions and permits us to gather all our job and desk definitions or knowledge sources in a central place.
Getting the information
For example we’ll use the identical Automated Dependent Surveillance Broadcast (ADS-B) knowledge we utilized in different posts and examples. For reference, ADS-B knowledge is generated and broadcast by planes whereas flying. The info consists of a airplane ID, altitude, latitude and longitude, velocity, and so forth.
To higher illustrate how MVs work, let’s execute a easy SQL question to retrieve the entire knowledge from our stream.
SELECT * FROM airplanes;
The creation of the “airplanes” desk has been omitted, however suffice it to say airplanes is a digital desk we have now created, which is fed by a stream of ADS-B knowledge flowing by means of a Kafka subject. Please examine our documentation to see how that’s performed. The question above will generate output like the next:
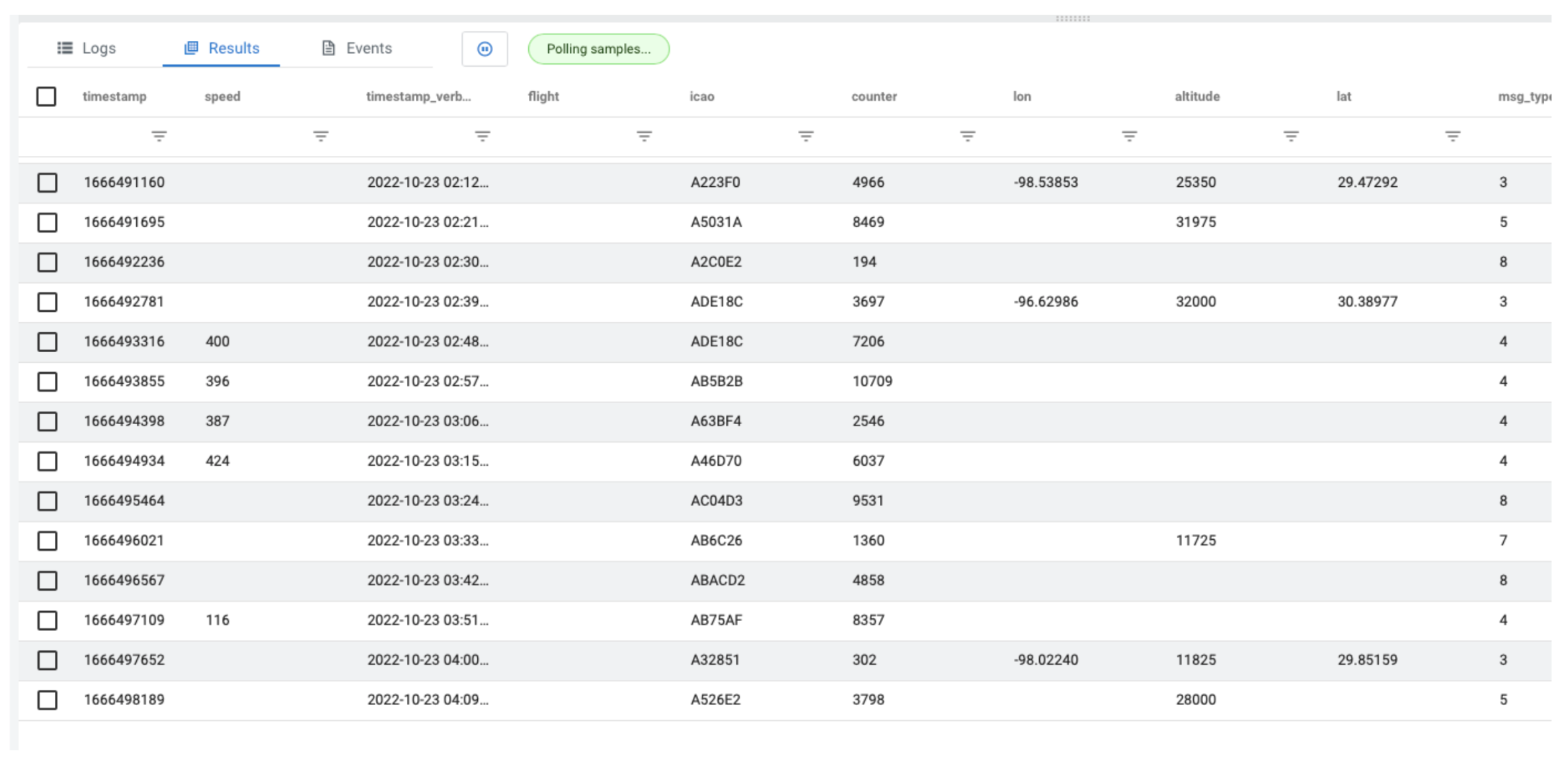 As you’ll be able to see from the output, there are every kind of fascinating knowledge factors. In our instance let’s give attention to altitude.
As you’ll be able to see from the output, there are every kind of fascinating knowledge factors. In our instance let’s give attention to altitude.
Flying excessive
From the SSB Console, click on on the “Materialized View” button on the highest proper:
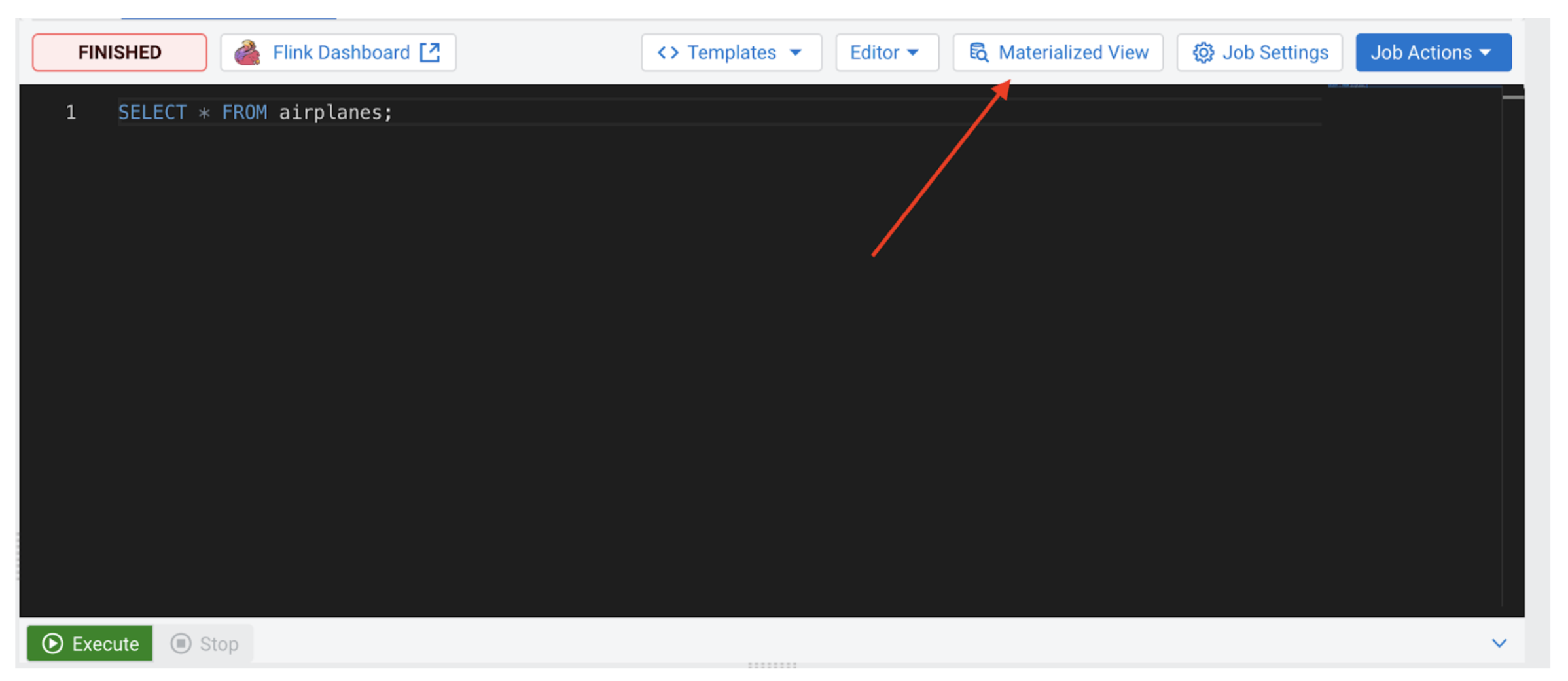
An MV configuration panel will open that may look much like the next:
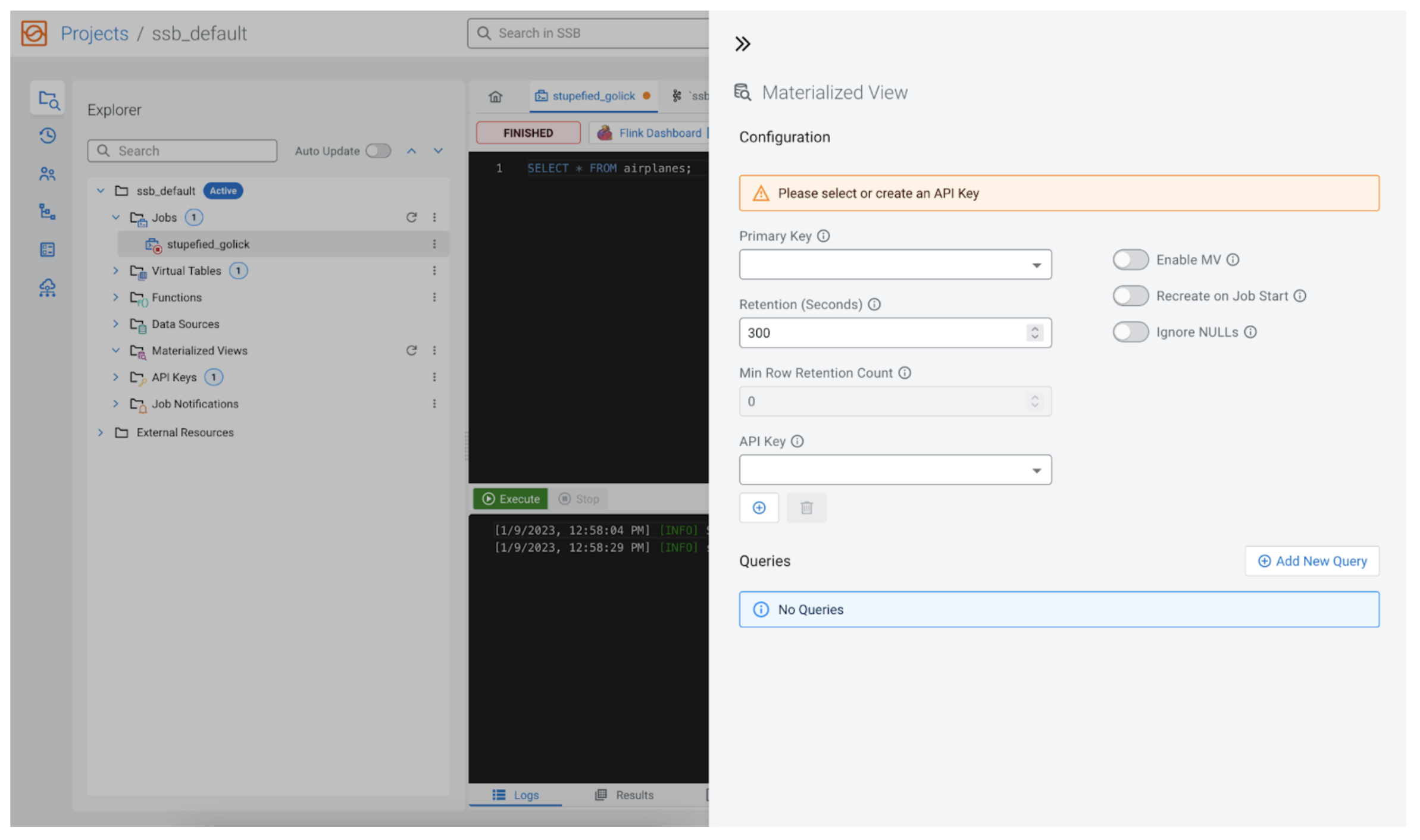
Configuration
SSB permits us to configure the brand new MV extensively, so we’ll undergo them right here.
Allow MV
For the MV to be accessible as soon as we have now completed configuring it, “Allow MV” should be enabled. This configuration additionally permits us to simply disable this characteristic sooner or later with out eradicating all the opposite settings.
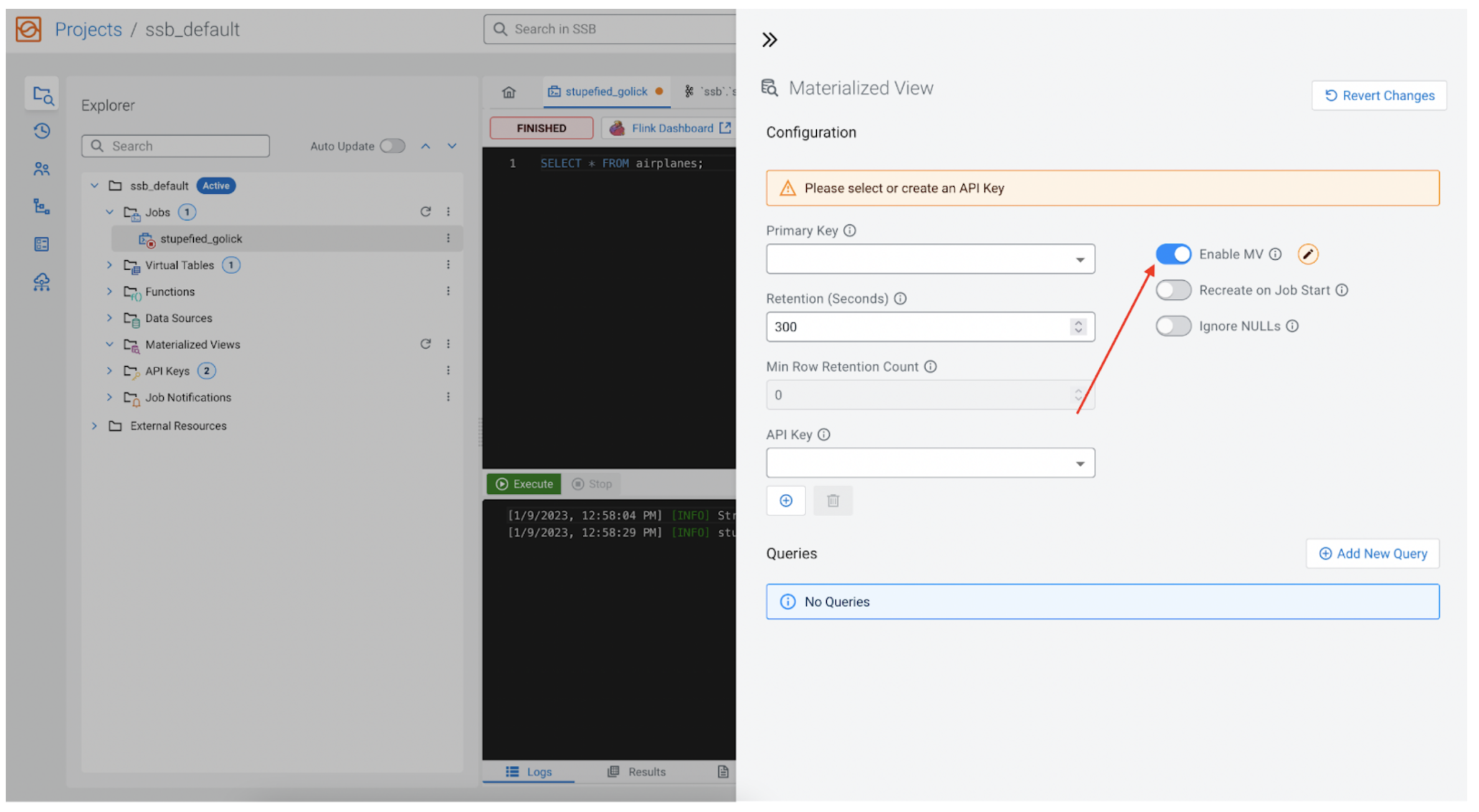
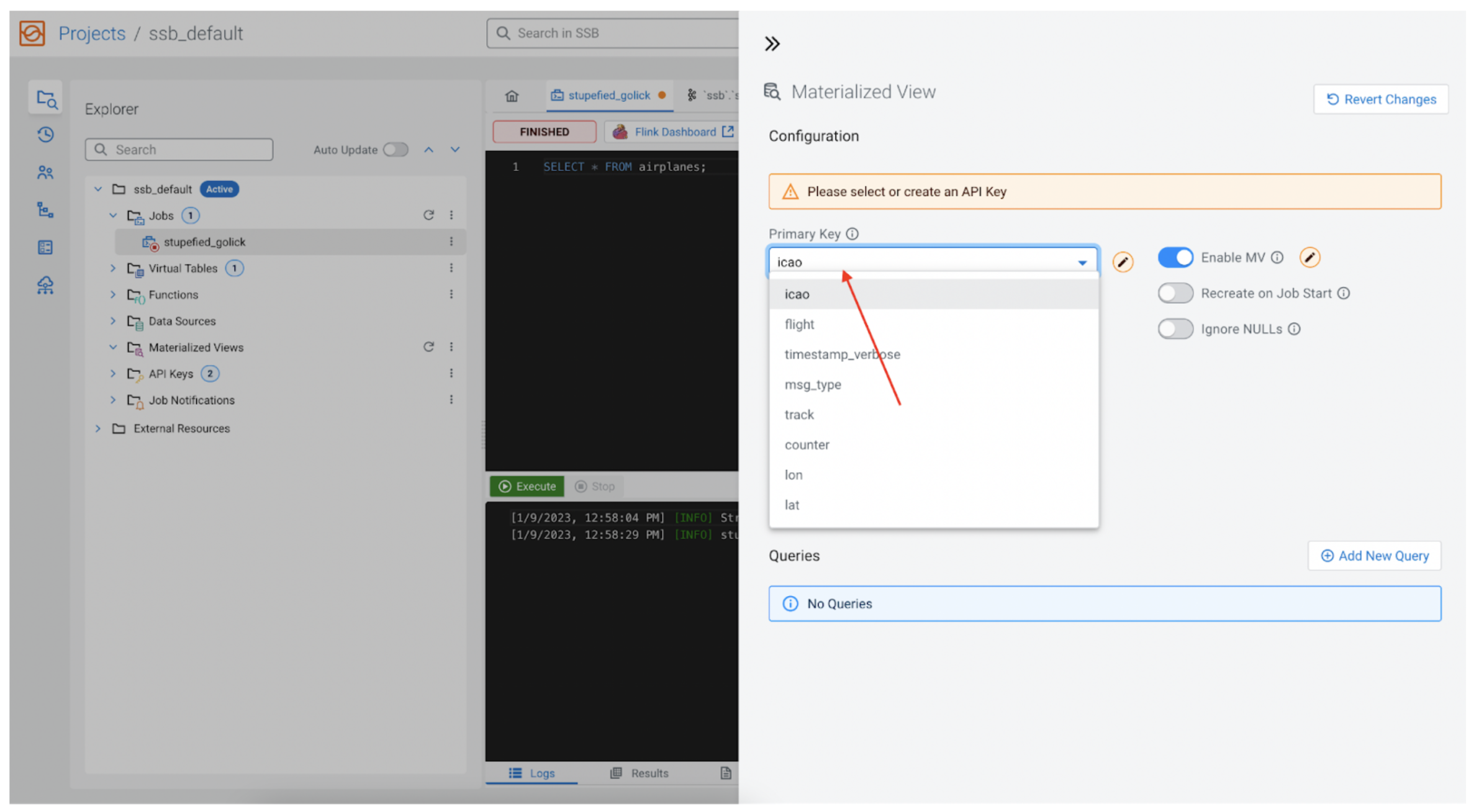
Major key
Each MV requires a major key, as this can be our major key within the underlying relational database as properly. The important thing is without doubt one of the fields returned by the SSB SQL question, and it’s accessible from the dropdown. In our case we’ll select icao, as a result of we all know that icao is the identification quantity for every airplane, so it’s a excellent match for the first key.
Retention and min row retention depend
This worth tells SSB how lengthy it ought to hold the information round earlier than eradicating it from the MV database. It’s set to 5 minutes by default. Every row within the MV is tagged with an insertion time, so if the row has been round longer than the “Retention (Seconds)” time then the row is eliminated. Be aware, there may be additionally an alternate technique for managing retention, and that’s the subject under the retention time, referred to as “Min Row Retention Depend,” which is used to point the minimal variety of rows we want to hold within the MV, no matter how outdated the information is likely to be. For instance let’s imagine, “We need to hold the final 1,000 rows irrespective of how outdated that knowledge is.” In that case we’d set “Retention (Seconds)” to 0, and set “Min Row Retention Depend” to 1,000.
For this instance we is not going to change the default values.
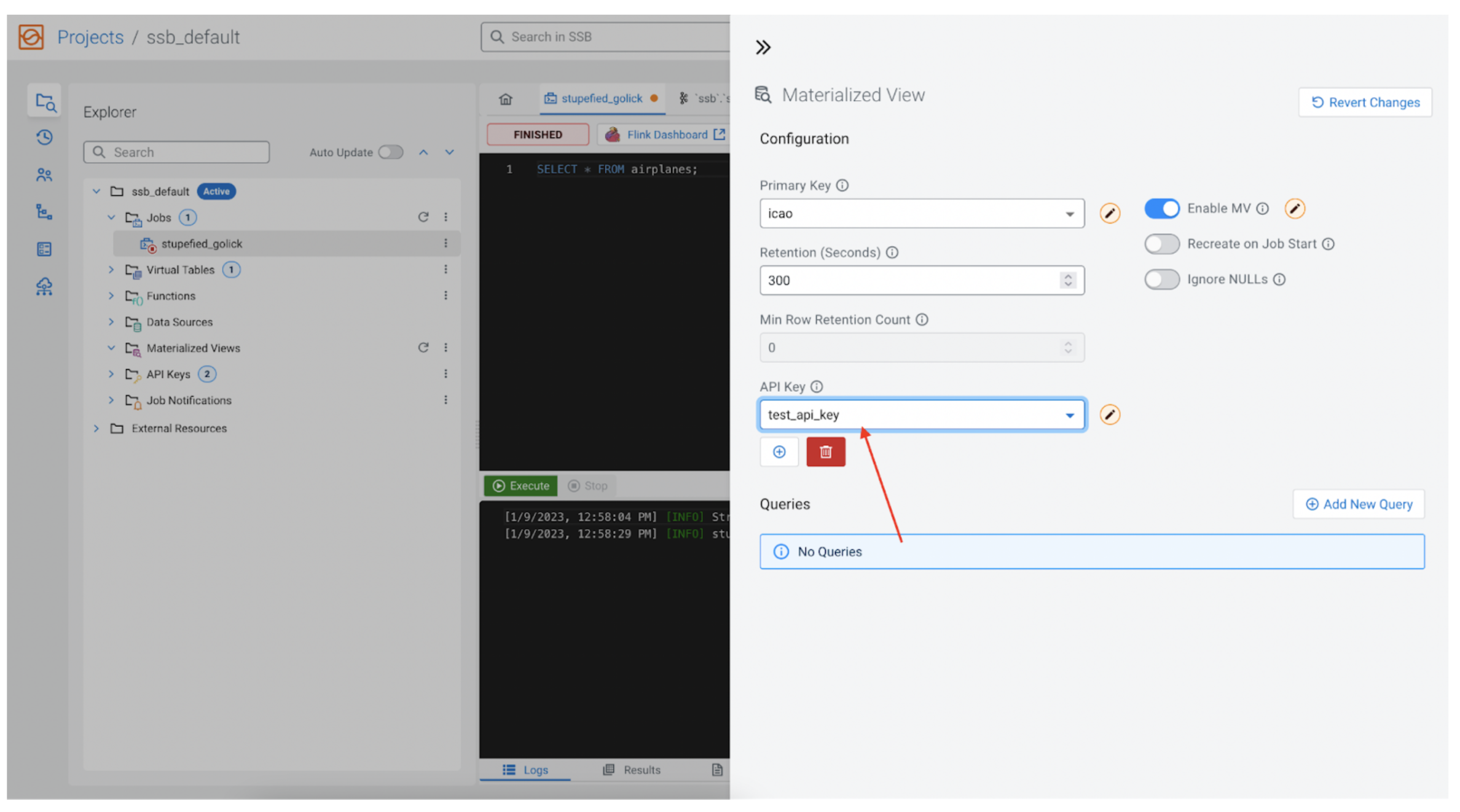
API key
As talked about earlier, each MV is related to a REST API. The REST API endpoint should be protected by an API Key. If none has been added but, one could be created right here as properly.
Queries
Lastly we get to probably the most fascinating half, choosing the right way to question our knowledge within the MV database.
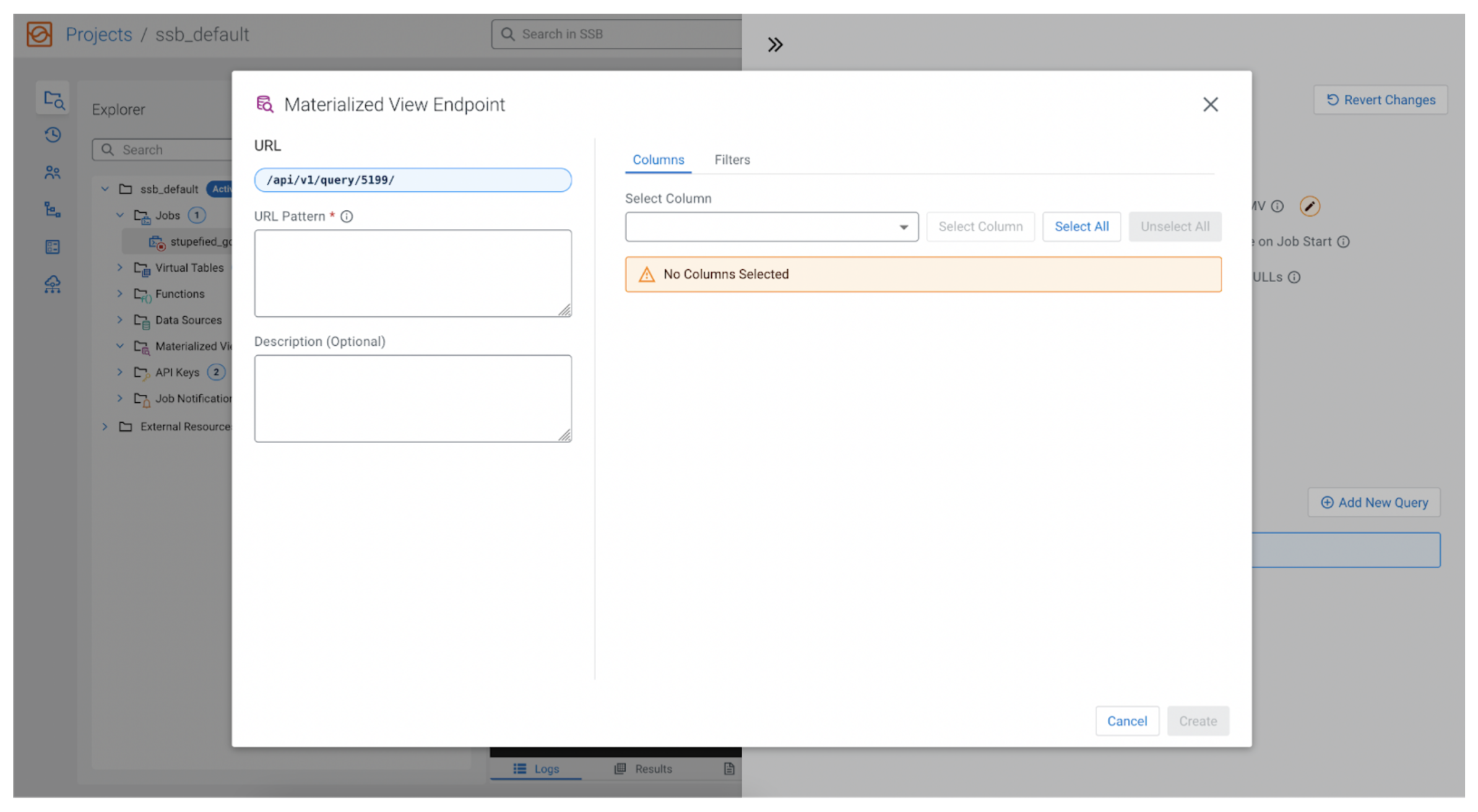
API endpoint
Clicking on the “Add New Question” button opens a pop-up that permits us to configure the REST API endpoint, in addition to choosing the information we want to question.
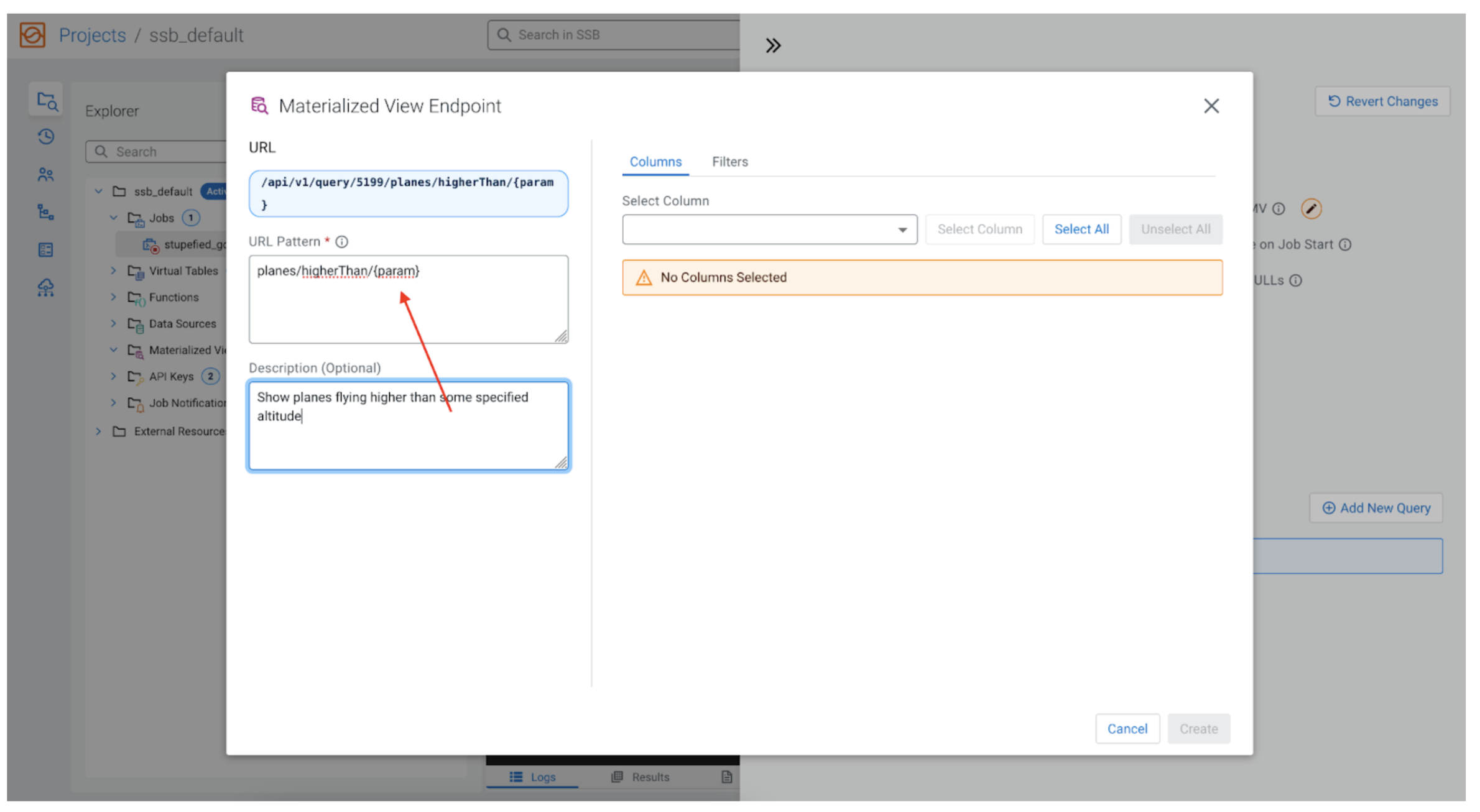
As we stated earlier, we have an interest within the airplane’s altitude, however let’s additionally add the flexibility to filter the sector altitude when calling the REST API. Our MV will be capable of solely present planes which might be flying larger than some consumer specified altitude (i.e., present planes flying larger than 10,000 ft). In that case within the “URL Sample” field we might enter:
planes/higherThan/{param}
Be aware the {param} worth. The URL sample can take parameters which might be specified inside curly brackets. After we retrieve knowledge for the MV, the REST API will map these parameters in our filters, so the consumer calling the endpoint can set the worth. See under.
Select the information
Now it’s time to choose what knowledge to gather as a part of our MV. The info fields we are able to select come from the preliminary SSB SQL question we wrote, so if we stated SELECT * FROM airplanes; the “Choose Columns” dropdown may have issues like fgentle, icao, lat, counter, altitude, and so forth. For our instance let’s select icao, lat, lon and altitude.
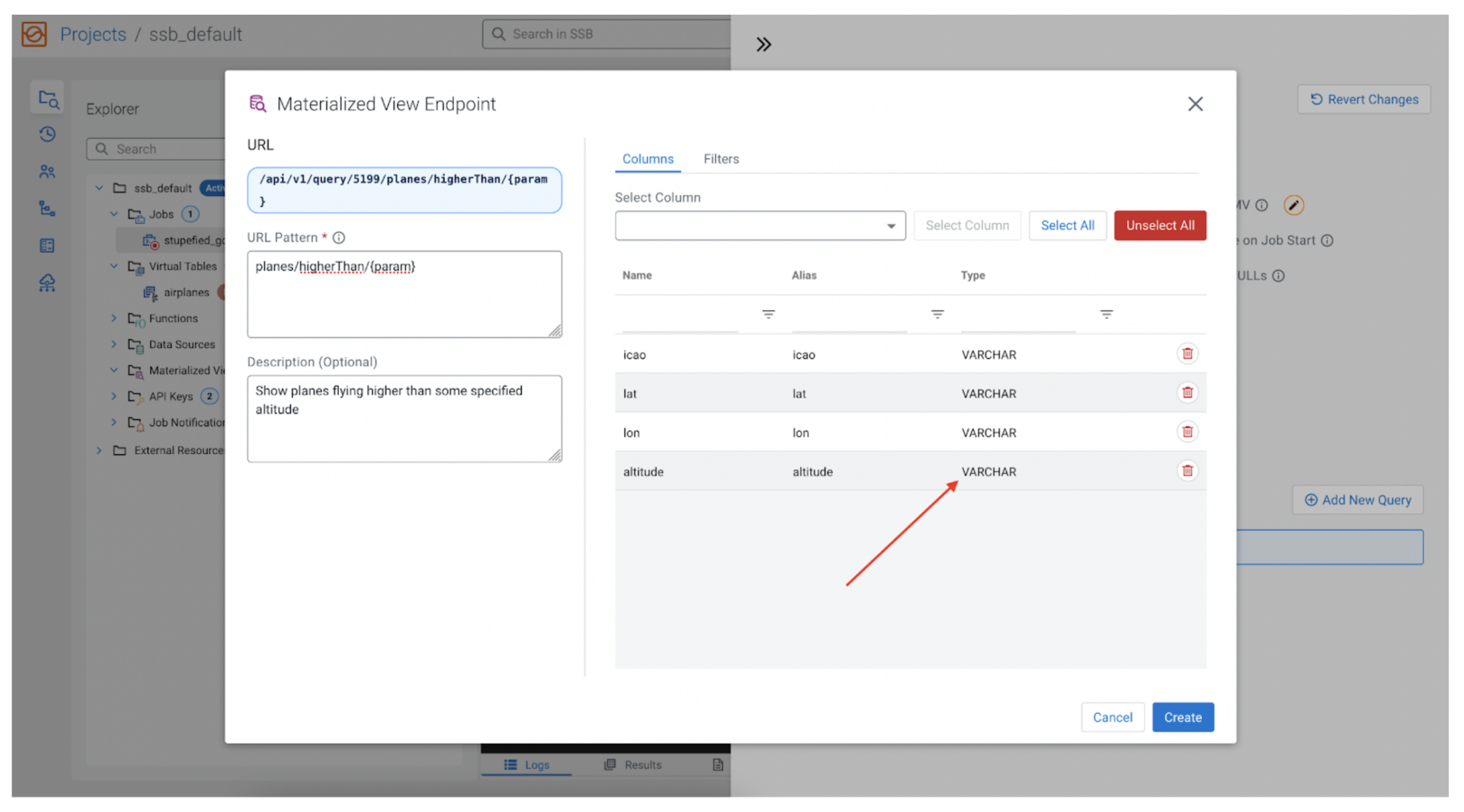
Oops
We have now an issue. The info fields within the stream, together with the altitude, are all of VARCHAR kind, making it infeasible to filter for numeric knowledge. We have to make a easy change to our SQL and convert the altitude into an INT, and name it top, to distinguish it from the unique altitude subject. Let’s change the SQL to the next:
SELECT *, CAST(altitude AS INT) AS top FROM airplanes;
Now we are able to change altitude with top, and use that to filter.
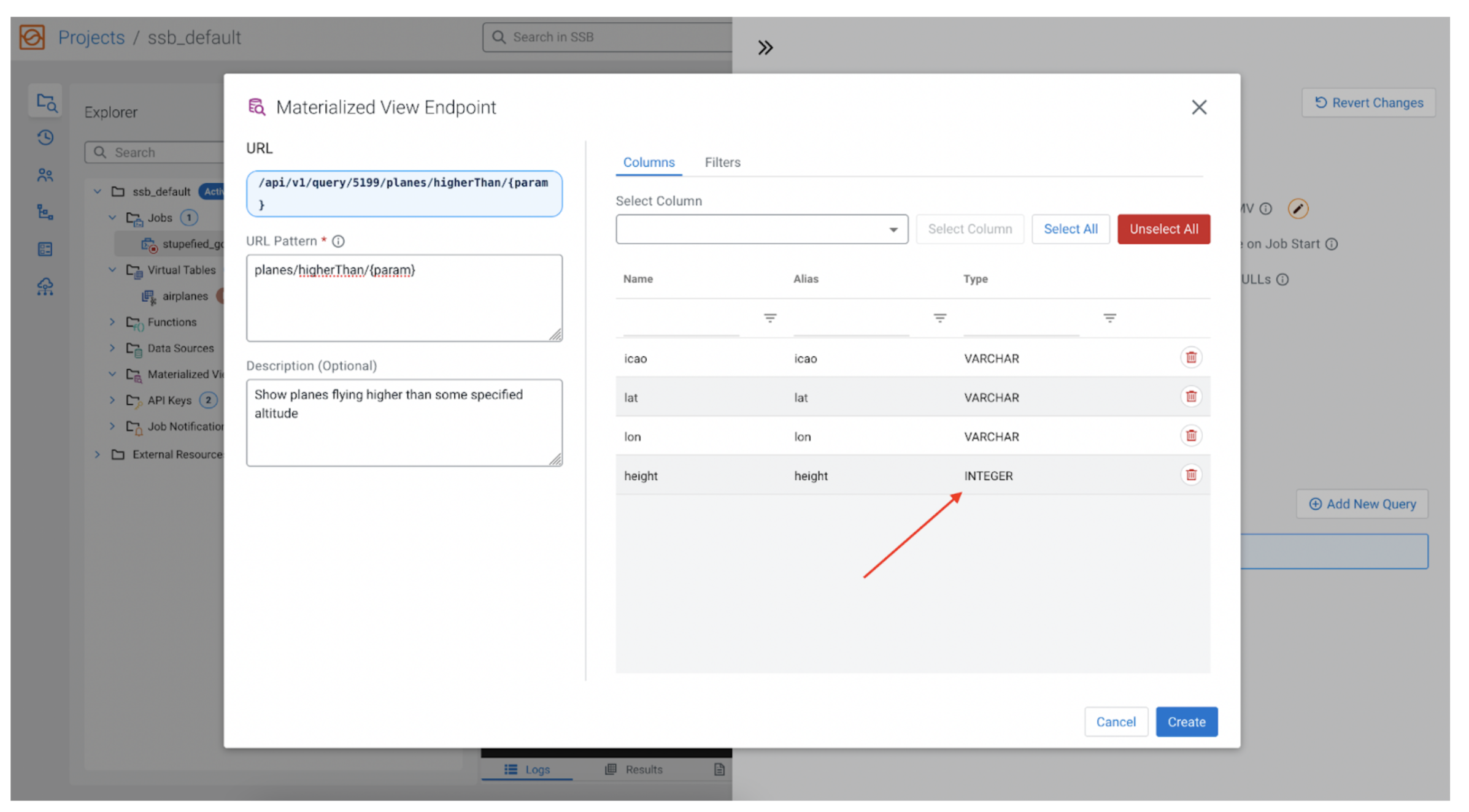
Filtering
Now to filter by top we have to map the parameter we beforehand created ({param}) to the top subject. By clicking on the “Filters” tab, after which the “+ Rule” button, we are able to add our filter.
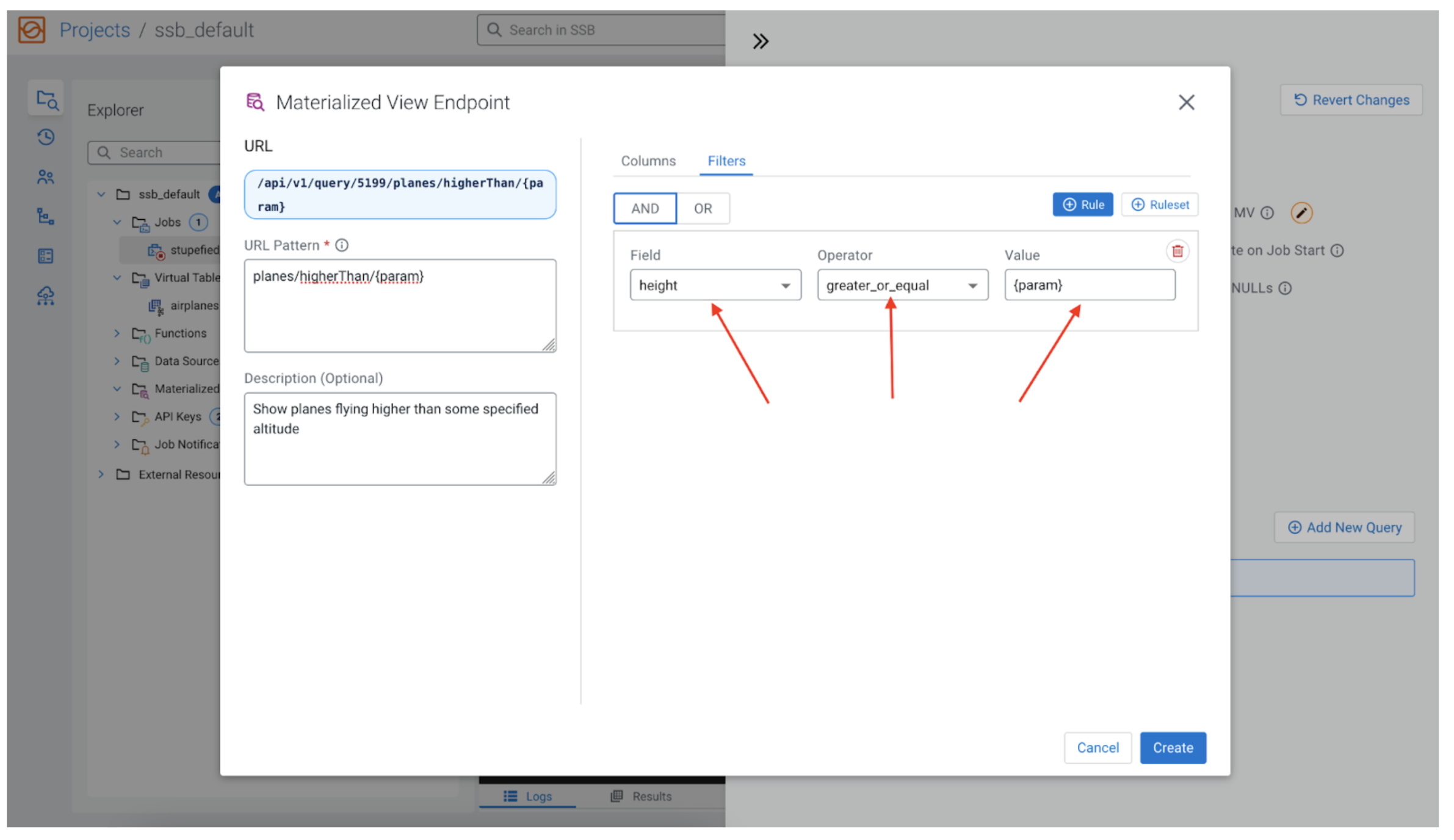
For the “Discipline” we select top, for the “Operator” we would like “greater_or_equal,” and for the “Worth” we use the {param} we used within the REST API endpoint. Now the MV question will filter the rows by the worth of top being higher than the worth that the consumer would give to {param} when issuing the REST request, for instance:
https://<host>/…/planes/higherThan/10000
That might output one thing much like the next:
[{"icao":"A28947","lat":"","lon":"","height":"30075"}]
Materialized views are a really helpful out-of-the-box knowledge sink, which give for the gathering of information in a tabular format, in addition to a configurable REST API question layer on high of that that can be utilized by third celebration functions.
Anyone can check out SSB utilizing the Stream Processing Neighborhood Version (CSP-CE). CE makes creating stream processors simple, as it may be performed proper out of your desktop or another growth node. Analysts, knowledge scientists, and builders can now consider new options, develop SQL-based stream processors regionally utilizing SQL Stream Builder powered by Flink, and develop Kafka Shoppers/Producers and Kafka Join Connectors, all regionally earlier than shifting to manufacturing in CDP.
[ad_2]