
[ad_1]
The Member Expertise
An insured member sometimes experiences their healthcare in two settings. The primary, and most relatable, is that with their healthcare suppliers, each main care physicians (PCPs) and specialists throughout a variety of varied inpatient and ambulatory settings. The opposite expertise encompasses the entire interactions with their well being plan, which consists of annual profit enrollment, declare funds, care discovery portals, and, from time to time, care administration groups which might be designed to assist member care.
These separate interactions by themselves are pretty complicated – some examples embrace scheduling companies, supplier remedy throughout all varieties of persistent and acute circumstances, medical reimbursement, and adjudication by means of a posh and prolonged billing cycle. Pretty invisible to the member (aside from an in- or out-of-network supplier standing) is a 3rd interplay between the insurer and supplier that performs a essential function in how healthcare is delivered, and that’s the supplier community providing.
Well being plans routinely negotiate charges and credential suppliers to take part of their plan choices. These community choices range throughout Medicare, Medicaid, and Industrial members, and may range throughout employer plan sponsors. Several types of networks could be connected to completely different insurance coverage merchandise, providing completely different incentives to all events concerned. For instance, slender networks are meant to supply decrease premiums and out-of-pocket prices in trade for having a smaller, native group of suppliers within the community.
Well being plans have incentives to optimize the supplier community providing to plan sponsors as a result of an optimum supplier community delivers higher high quality take care of sufferers, at a decrease value. Such networks can higher synthesize care remedy plans, cut back fraud and waste, and provide equitable entry to care to call a couple of advantages.
Constructing an optimum community is simpler mentioned than completed, nonetheless.
Optimizations Behind the Scenes
Optimization shouldn’t be easy. The Healthcare Effectiveness Information and Info Set (HEDIS) is a software utilized by greater than 90 p.c of U.S. well being plans to measure efficiency on vital dimensions of care and repair. A community excelling at a HEDIS measure of high quality equivalent to Breast Most cancers Screening shouldn’t be helpful for a inhabitants that does not consist of girls over the age of fifty. Evaluation is fluid because the wants of a member inhabitants and strengths of a doctor group constantly evolve.
Compounding the evaluation of aligning membership must supplier capabilities is knowing who has entry to care from a geospatial viewpoint. In different phrases, are members in a position to bodily entry acceptable supplier care as a result of that supplier is reachable when it comes to distance between areas. That is the place Databricks, constructed on the extremely scalable compute engine Apache Spark™, differentiates itself from historic approaches to the geospatial neighbor downside.
Answer Accelerator for Scalable Community Evaluation
Healthcare geospatial comparisons are typically phrased as “Who’re the closest ‘X’ suppliers situated inside ‘Y’ distance of members?” That is the foundational query to grasp who can present the best high quality of care or present speciality companies to a given member inhabitants. Answering this query traditionally falls into both geohashing, an method that primarily subdivides area on a map and buckets factors in a grid collectively – permitting for scalability however resulting in outcomes that lack precision, or direct comparability of factors and distance which is correct however not scalable.
Databricks solves for each scalability and accuracy with a answer accelerator by leveraging varied strengths inside the Spark ecosystem. Enter framing matches the final query of, given a “Y” radius, return the closest “X” areas, and information enter requires latitude/longitude values and optionally accepts an identifier discipline that can be utilized to extra simply relate information.
Configuration parameters within the accelerator embrace setting the diploma of parallelism to distribute compute for sooner runtimes,, a serverless connection string (serverless is a key element to the scalability and additional described beneath), and a brief working desk that’s used as a quick information cache operation and optimized utilizing Spark Indexes (ZOrder) as a placeholder on your information.
Output from this answer accelerator gives the origin location in addition to an array of all surrounding neighbors, their distances from the origin, and the search time for every document (to permit additional optimizations and tuning).
So how & why does this scalability work?
It is very important notice that Spark is a horizontally scalable platform. Which means, it could possibly scale comparable duties throughout an infinite variety of machines. Utilizing this sample, if we’re in a position to compute a extremely environment friendly calculation for one member and its nearest neighboring supplier areas, we will infinitely scale this answer utilizing Spark.
For the quick neighborhood search of a single member, we’d like a fairly environment friendly pruning approach in order that we don’t want to go looking your entire supplier dataset each single time and really quick information retrieval (constantly sub-second response). The preliminary method to pruning makes use of a kind of geohash for this, however sooner or later will transfer to a extra environment friendly methodology with Databricks H3 representations. For very quick retrieval, we initially explored utilizing a cloud NoSQL, however we achieved drastically higher outcomes utilizing Databricks Serverless SQL and Spark indexes (the unique code for CosmosDB is included and could be carried out on different NoSQLs). The structure for the Answer Accelerator appears to be like like this:
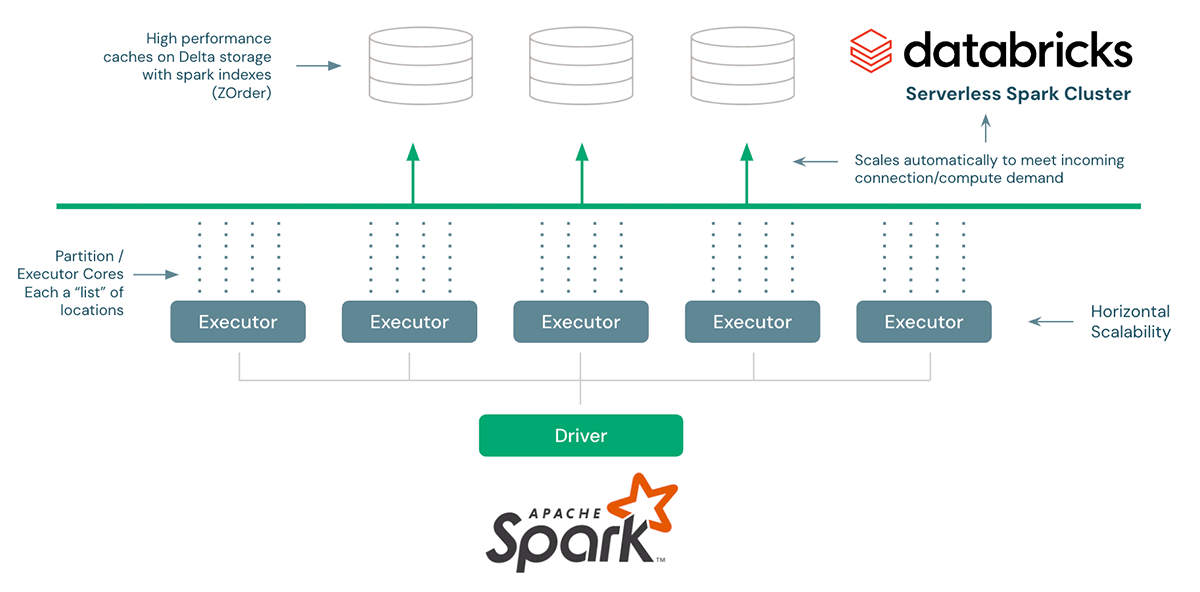
Spark historically has neither been environment friendly on small queries nor gives scalable JDBC connection administration to run various, massively parallel workloads. That is not the case when utilizing the Databricks Lakehouse, which incorporates Serverless SQL and Delta Lake together with strategies like ZOrder indexes. As well as, Databricks’ latest announcement of liquid clustering will provide an much more performant different to ZOrdering.
And eventually, a fast notice on scaling this accelerator. As a result of runtimes are depending on a mix of non-trivial elements just like the density of the areas, radius of search, and max outcomes returned, we subsequently present sufficient visibility into efficiency to have the ability to tune this workload. The horizontal scale beforehand talked about happens by means of growing the variety of partitions within the configuration parameters. Some fast math with the full variety of data, common lookup time, and variety of partitions tells you anticipated runtime. As a common rule, have 1 CPU aligned to every partition (this quantity can range relying on circumstances).
Pattern Evaluation Use Instances
Evaluation at scale can present precious info like measuring equitable entry to care, offering value efficient suggestions on imaging or diagnostic testing areas, and with the ability to appropriately refer members to the best performing suppliers reachable. Evaluating the appropriate website of take care of a member, much like the aggressive dynamics seen in well being plan value transparency, is a mix of each value and high quality.
These use instances lead to tangible financial savings and higher outcomes for sufferers. As well as, nearest neighbor searches could be utilized past only for a well being plan community. Suppliers are in a position to determine affected person utilization patterns, provide chains can higher handle stock and re-routing, and pharmaceutical corporations can enhance detailing applications.
Extra Methods to Construct Smarter Networks with Higher High quality Information
We perceive not each healthcare group could also be able the place they’re prepared to research supplier information within the context of community optimization. Ribbon Well being, a corporation specializing in supplier listing administration and information high quality, affords constructed on Databricks options to offer a foundational layer that may assist organizations extra shortly and successfully handle their supplier information.
Ribbon Well being is among the early companions represented within the Databricks Market, an open market for exchanging information merchandise equivalent to datasets, notebooks, dashboards, and machine studying fashions. Now you can discover Ribbon Well being’s Supplier Listing & Location Listing on the Databricks Market so well being plans and care suppliers/navigators can begin utilizing this information as we speak.
The info consists of NPIs, observe areas, contact info with confidence scores, specialties, location varieties, relative value and expertise, areas of focus, and accepted insurance coverage. The dataset additionally has broad protection, together with 99.9% of suppliers, 1.7M distinctive service areas, and insurance coverage protection for 90.1% of lives coated throughout all strains of enterprise and payers. The info is constantly checked and cross-checked to make sure essentially the most up-to-date info is proven.
Supplier networks, given their function in value and high quality, are foundational to each the efficiency of the well being plan and member expertise. With these information units, organizations can now extra effectively handle, customise, and keep their very own supplier information.
[ad_2]