
[ad_1]
The predictive high quality of a machine studying mannequin is a direct reflection of the standard of knowledge used to coach and serve the mannequin. Normally, the options, or enter information to the mannequin, are calculated upfront, saved, after which seemed up and served to the mannequin for inference. The problem arises when these options can’t be pre-calculated, as mannequin efficiency typically correlates instantly with the freshness of the info used for function computation. To simplify the problem of serving this class of options, we’re excited to announce On Demand Characteristic Computation.
Use instances like suggestions, safety programs, and fraud detection require that options be computed on-demand on the time of scoring these fashions. Eventualities embody:
- When the enter information for options is just obtainable on the time of mannequin serving. For example,
distance_from_restaurantrequires the final recognized location of a consumer decided by a cell gadget. - Conditions the place the worth of a function varies relying on the context wherein it is used. Engagement metrics ought to be interpreted very in another way when
device_typeis cell, versus desktop. - Situations the place it is cost-prohibitive to precompute, retailer, and refresh options. A video streaming service might have tens of millions of customers and tens of hundreds of films, making it prohibitive to precompute a function like
avg_rating_of_similar_movies.
With a view to assist these use instances, options have to be computed at inference time. Nonetheless, function computation for mannequin coaching is often carried out utilizing cost-efficient and throughput-optimized frameworks like Apache Spark(™). This poses two main issues when these options are required for real-time scoring:
- Human effort, delays, and Coaching/Serving Skew: The structure all-too-often necessitates rewriting function computations in server-side, latency-optimized languages like Java or C++. This not solely introduces the potential of training-serving skew because the options are created in two totally different languages, but in addition requires machine studying engineers to take care of and sync function computation logic between offline and on-line programs.
- Architectural complexity to compute and supply options to fashions. These function engineering pipelines programs must be deployed and up to date in tandem with served fashions. When new mannequin variations are deployed, they require new function definitions. Such architectures additionally add pointless deployment delays. Machine studying engineers want to make sure that new function computation pipelines and endpoints are unbiased of the programs in manufacturing with a purpose to keep away from operating up in opposition to price limits, useful resource constraints, and community bandwidths.
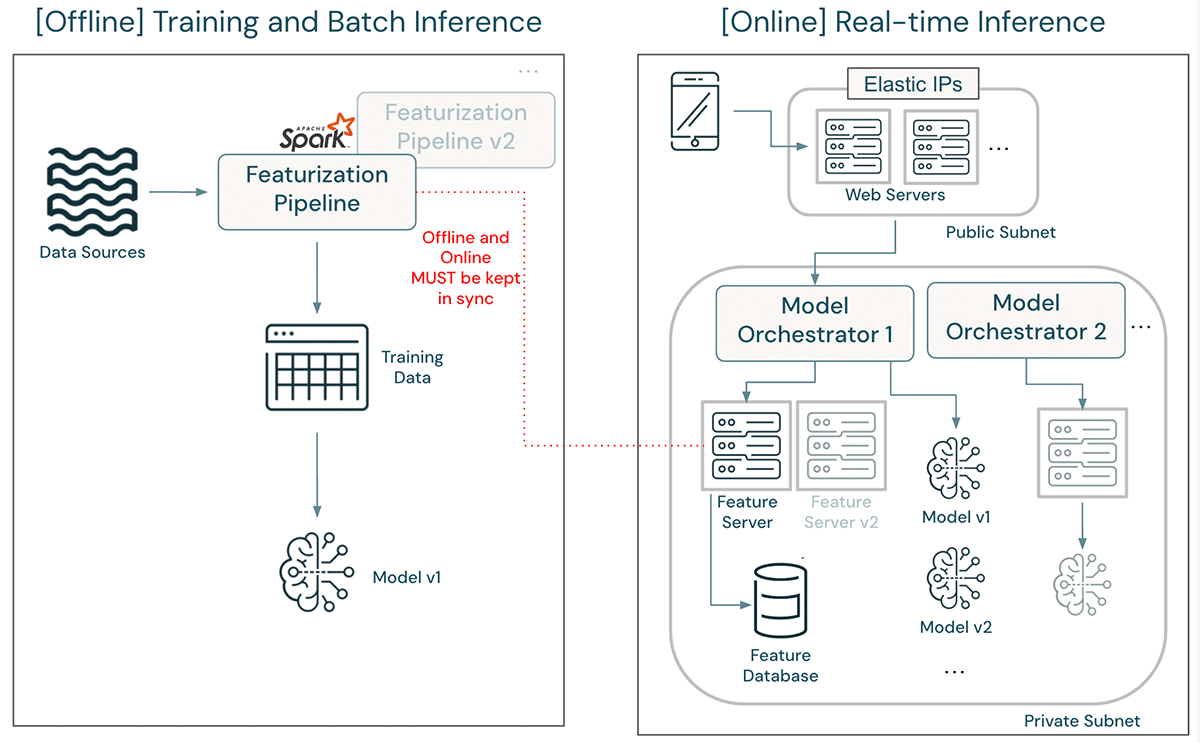
Within the above structure, updating a function definition could be a main endeavor. An up to date featurization pipeline have to be developed and deployed in tandem with the unique, which continues to assist coaching and batch inference with the outdated function definition. The mannequin have to be retrained and validated utilizing the up to date function definition. As soon as it’s cleared for deployment, engineers should first rewrite function computation logic within the function server and deploy an unbiased function server model in order to not have an effect on manufacturing visitors. After deployment, quite a few assessments ought to be run to make sure that the up to date mannequin’s efficiency is similar as seen throughout improvement. The mannequin orchestrator have to be up to date to direct visitors to the brand new mannequin. Lastly, after some baking time, the outdated mannequin and outdated function server may be taken down.
To simplify this structure, enhance engineering velocity, and enhance availability, Databricks is launching assist for on-demand function computation. The performance is constructed instantly into Unity Catalog, simplifying the end-to-end consumer journey to create and deploy fashions.
On-demand options helped to considerably scale back the complexity of our Characteristic Engineering pipelines. With On-demand options we’re in a position to keep away from managing sophisticated transformations which are distinctive to every of our shoppers. As an alternative we are able to merely begin with our set of base options and remodel them, per consumer, on-demand throughout coaching and inference. Really, on-demand options have unlocked our skill to construct our subsequent technology of fashions. – Chris Messier, Senior Machine Studying Engineer at MissionWired
Utilizing Capabilities in Machine Studying Fashions
With Characteristic Engineering in Unity Catalog, information scientists can retrieve pre-materialized options from tables and may compute on-demand options utilizing capabilities. On-demand computation is expressed as Python Consumer-Outlined Capabilities (UDFs), that are ruled entities in Unity Catalog. Capabilities are created in SQL, and may then be used throughout the lakehouse in SQL queries, dashboards, notebooks, and now to compute options in real-time fashions.
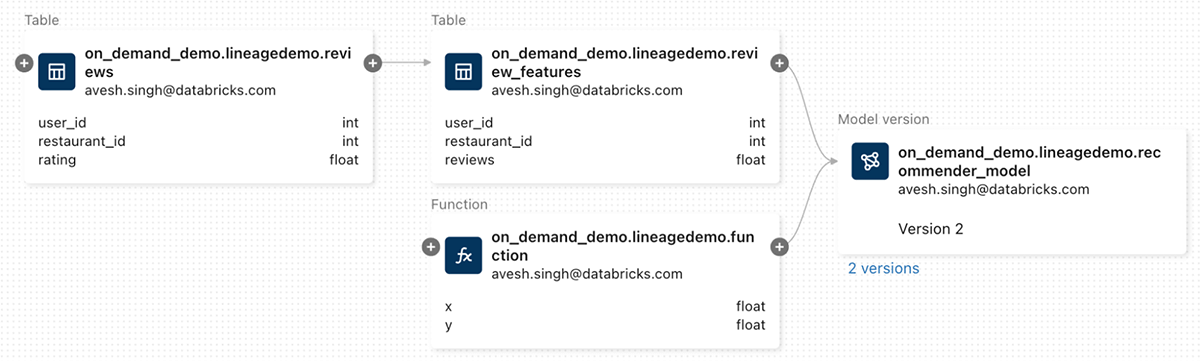
The UC lineage graph information dependencies of the mannequin on information and capabilities.
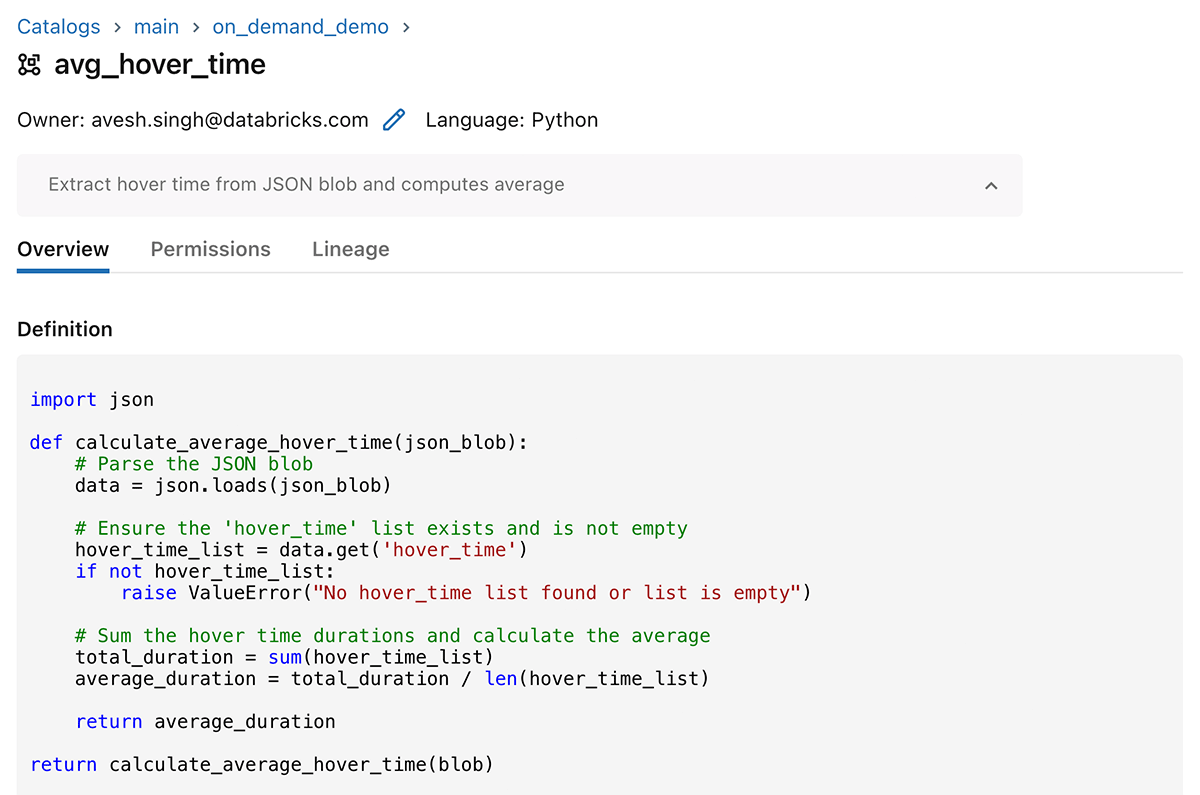
CREATE OR REPLACE FUNCTION principal.on_demand_demo.avg_hover_time(blob STRING)
RETURNS FLOAT
LANGUAGE PYTHON
COMMENT "Extract hover time from JSON blob and computes common"
AS $$
import json
def calculate_average_hover_time(json_blob):
# Parse the JSON blob
information = json.masses(json_blob)
# Make sure the 'hover_time' checklist exists and is not empty
hover_time_list = information.get('hover_time')
if not hover_time_list:
elevate ValueError("No hover_time checklist discovered or checklist is empty")
# Sum the hover time durations and calculate the common
total_duration = sum(hover_time_list)
average_duration = total_duration / len(hover_time_list)
return average_duration
return calculate_average_hover_time(blob)
$$To make use of a perform in a mannequin, embody it within the name to create_training_set.
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
options = [
FeatureFunction(
udf_name="main.on_demand_demo.avg_hover_time",
output_name="on_demand_output",
input_bindings={"blob": "json_blob"},
),
...
]
training_set = fs.create_training_set(
raw_df, feature_lookups=options, label="label", exclude_columns=["id"]
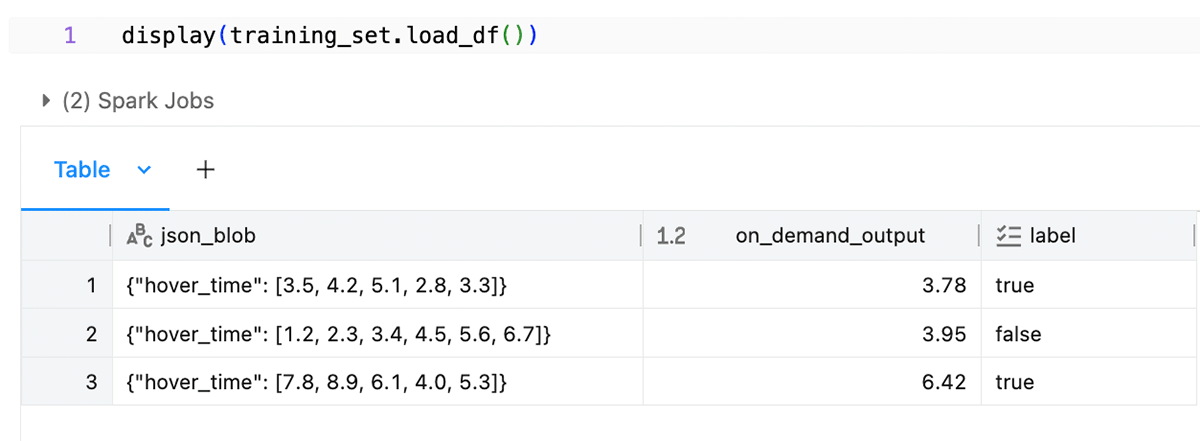
)The perform is executed by Spark to generate coaching information on your mannequin.
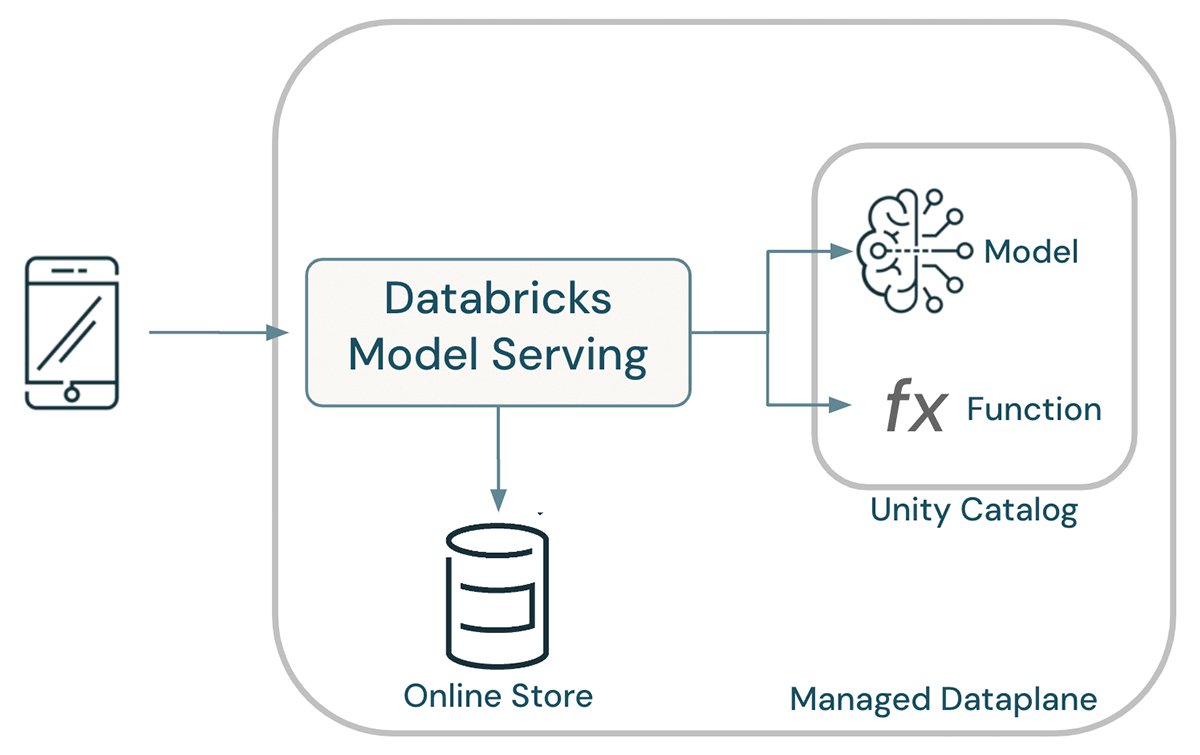
The perform can also be executed in real-time serving utilizing native Python and pandas. Whereas Spark shouldn’t be concerned within the real-time pathway, the identical computation is assured to be equal to that used at coaching time.
A Simplified Structure
Fashions, capabilities, and information all coexist inside Unity Catalog, enabling unified governance. A shared catalog allows information scientists to re-use options and capabilities for modeling, making certain consistency in how options are calculated throughout a company. When served, mannequin lineage is used to find out the capabilities and tables for use as enter to the mannequin, eliminating the potential of training-serving skew. General, this leads to a dramatically simplified structure.
Lakehouse AI automates the deployment of fashions: when a mannequin is deployed, Databricks Mannequin Serving mechanically deploys all capabilities required to allow dwell computation of options. At request time, pre-materialized options are seemed up from on-line shops and on-demand options are computed by executing the our bodies of their Python UDFs.
Easy Instance – Common hover time
On this instance, an on-demand function parses a JSON string to extract an inventory of hover instances on a webpage. These instances are averaged collectively, and the imply is handed as a function to a mannequin.
The question the mannequin, cross a JSON blob containing hover instances. For instance:
curl
-u token:$DATABRICKS_TOKEN
-X POST
-H "Content material-Sort: utility/json"
-d '{
"dataframe_records": [
{"json_blob": "{"hover_time": [5.5, 2.3, 10.3]}"}
]
}'
<host>/serving-endpoints/<endpoint_name>/invocationsThe mannequin will compute the common hover time on-demand, then will rating the mannequin utilizing common hover time as a function.
Subtle Instance – Distance to restaurant
On this instance, a restaurant advice mannequin takes a JSON string containing a consumer’s location and a restaurant id. The restaurant’s location is seemed up from a pre-materialized function desk revealed to a web-based retailer, and an on-demand function computes the gap from the consumer to the restaurant. This distance is handed as enter to a mannequin.
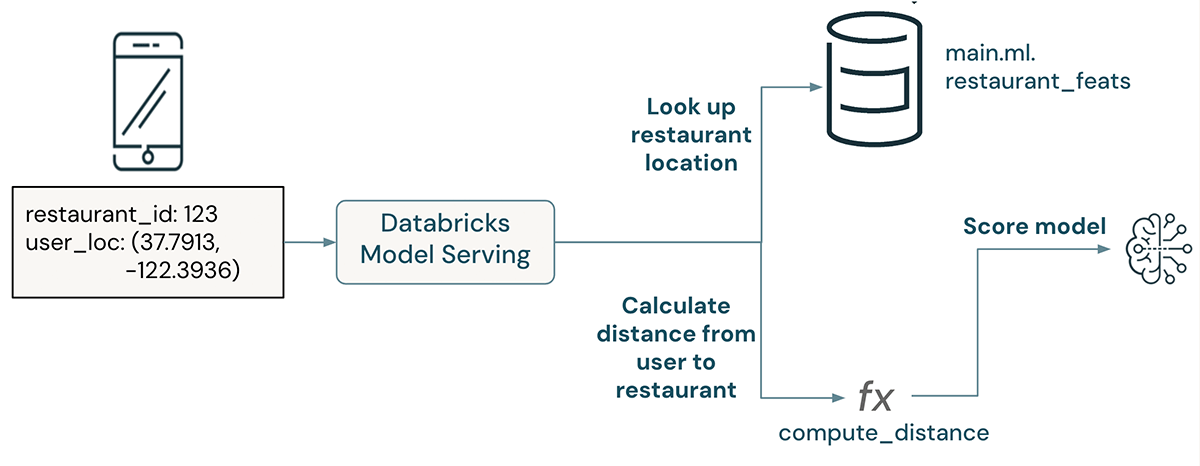
Discover that this instance features a lookup of a restaurant’s location, then a subsequent transformation to compute the gap from this restaurant to the consumer.
Be taught Extra
For API documentation and extra steering, see Compute options on demand utilizing Python user-defined capabilities.
Have a use case you’d prefer to share with Databricks? Contact us at [email protected].
[ad_2]