
[ad_1]
It’s no secret to anybody that high-performing ML fashions must be equipped with massive volumes of high quality coaching knowledge. With out having the info, there’s hardly a approach a company can leverage AI and self-reflect to turn into extra environment friendly and make better-informed choices. The method of changing into a data-driven (and particularly AI-driven) firm is understood to be not simple.
28% of corporations that undertake AI cite lack of entry to knowledge as a purpose behind failed deployments. – KDNuggets
Moreover, there are points with errors and biases inside present knowledge. They’re considerably simpler to mitigate by numerous processing strategies, however this nonetheless impacts the provision of reliable coaching knowledge. It’s a significant issue, however the lack of coaching knowledge is a a lot tougher drawback, and fixing it’d contain many initiatives relying on the maturity stage.
Apart from knowledge availability and biases there’s one other side that is essential to say: knowledge privateness. Each corporations and people are constantly selecting to stop knowledge they personal for use for mannequin coaching by third events. The shortage of transparency and laws round this matter is well-known and had already turn into a catalyst of lawmaking throughout the globe.
Nonetheless, within the broad panorama of data-oriented applied sciences, there’s one which goals to unravel the above-mentioned issues from a bit of sudden angle. This expertise is artificial knowledge. Artificial knowledge is produced by simulations with numerous fashions and eventualities or sampling strategies of present knowledge sources to create new knowledge that’s not sourced from the true world.
Artificial knowledge can substitute or increase present knowledge and be used for coaching ML fashions, mitigating bias, and defending delicate or regulated knowledge. It’s low cost and could be produced on demand in massive portions in keeping with specified statistics.
Artificial datasets hold the statistical properties of the unique knowledge used as a supply: strategies that generate the info acquire a joint distribution that additionally could be custom-made if crucial. Consequently, artificial datasets are just like their actual sources however don’t comprise any delicate data. That is particularly helpful in extremely regulated industries akin to banking and healthcare, the place it might take months for an worker to get entry to delicate knowledge due to strict inside procedures. Utilizing artificial knowledge on this surroundings for testing, coaching AI fashions, detecting fraud and different functions simplifies the workflow and reduces the time required for improvement.
All this additionally applies to coaching massive language fashions since they’re skilled totally on public knowledge (e.g. OpenAI ChatGPT was skilled on Wikipedia, components of internet index, and different public datasets), however we predict that it’s artificial knowledge is an actual differentiator going additional since there’s a restrict of obtainable public knowledge for coaching fashions (each bodily and authorized) and human created knowledge is pricey, particularly if it requires consultants.
Producing Artificial Knowledge
There are numerous strategies of manufacturing artificial knowledge. They are often subdivided into roughly 3 main classes, every with its benefits and downsides:
- Stochastic course of modeling. Stochastic fashions are comparatively easy to construct and don’t require a whole lot of computing sources, however since modeling is concentrated on statistical distribution, the row-level knowledge has no delicate data. The best instance of stochastic course of modeling could be producing a column of numbers based mostly on some statistical parameters akin to minimal, most, and common values and assuming the output knowledge follows some recognized distribution (e.g. random or Gaussian).
- Rule-based knowledge era. Rule-based techniques enhance statistical modeling by together with knowledge that’s generated in keeping with guidelines outlined by people. Guidelines could be of varied complexity, however high-quality knowledge requires advanced guidelines and tuning by human consultants which limits the scalability of the strategy.
- Deep studying generative fashions. By making use of deep studying generative fashions, it’s doable to coach a mannequin with actual knowledge and use that mannequin to generate artificial knowledge. Deep studying fashions are in a position to seize extra advanced relationships and joint distributions of datasets, however at the next complexity and compute prices.
Additionally, it’s value mentioning that present LLMs may also be used to generate artificial knowledge. It doesn’t require intensive setup and could be very helpful on a smaller scale (or when achieved simply on a person request) as it might present each structured and unstructured knowledge, however on a bigger scale it may be costlier than specialised strategies. Let’s not overlook that state-of-the-art fashions are vulnerable to hallucinations so statistical properties of artificial knowledge that comes from LLM ought to be checked earlier than utilizing it in eventualities the place distribution issues.
An fascinating instance that may function an illustration of how the usage of artificial knowledge requires a change in strategy to ML mannequin coaching is an strategy to mannequin validation.
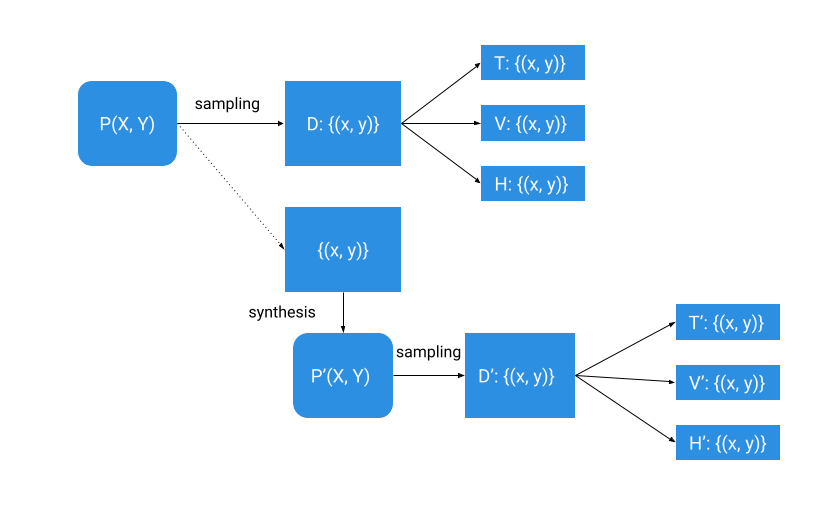
In conventional knowledge modeling, we have now a dataset (D) that may be a set of observations drawn from some unknown real-world course of (P) that we wish to mannequin. We divide that dataset right into a coaching subset (T), a validation subset (V) and a holdout (H) and use it to coach a mannequin and estimate its accuracy.
To do artificial knowledge modeling, we synthesize a distribution P’ from our preliminary dataset and pattern it to get the artificial dataset (D’). We subdivide the artificial dataset right into a coaching subset (T’), a validation subset (V’), and a holdout (H’) like we subdivided the true dataset. We would like distribution P’ to be as virtually near P as doable since we would like the accuracy of a mannequin skilled on artificial knowledge to be as near the accuracy of a mannequin skilled on actual knowledge (in fact, all artificial knowledge ensures ought to be held).
When doable, artificial knowledge modeling must also use the validation (V) and holdout (H) knowledge from the unique supply knowledge (D) for mannequin analysis to make sure that the mannequin skilled on artificial knowledge (T’) performs effectively on real-world knowledge.
So, a great artificial knowledge answer ought to permit us to mannequin P(X, Y) as precisely as doable whereas conserving all privateness ensures held.
Though the broader use of artificial knowledge for mannequin coaching requires altering and bettering present approaches, in our opinion, it’s a promising expertise to deal with present issues with knowledge possession and privateness. Its correct use will result in extra correct fashions that may enhance and automate the choice making course of considerably decreasing the dangers related to the usage of non-public knowledge.
In regards to the creator
Nick Volynets is a senior knowledge engineer working with the workplace of the CTO the place he enjoys being on the coronary heart of DataRobot innovation. He’s desirous about massive scale machine studying and obsessed with AI and its affect.
[ad_2]