
[ad_1]

Elevate your AI purposes with our newest utilized ML prototype
At Cloudera, we constantly attempt to empower organizations to unlock the total potential of their information, catalyzing innovation and driving actionable insights. And so we’re thrilled to introduce our newest utilized ML prototype (AMP)—a big language mannequin (LLM) chatbot custom-made with web site information utilizing Meta’s Llama2 LLM and Pinecone’s vector database.
Innovation in structure
To be able to leverage their very own distinctive information within the deployment of an LLM’s (or different generative mannequin), organizations should coordinate pipelines to constantly feed the system contemporary information for use for mannequin refinement and augmentation.
This AMP is constructed on the inspiration of one among our earlier AMPs, with the extra enhancement of enabling clients to create a information base from information on their very own web site utilizing Cloudera DataFlow (CDF) after which increase inquiries to the chatbot from that very same information base in Pinecone. DataFlow helps our clients rapidly assemble pre-built elements to construct information pipelines that may seize, course of, and distribute any information, wherever in actual time. Your complete pipeline for this AMP is obtainable in a configurable ReadyFlow template that includes a new connector to the Pinecone vector database to additional speed up deployment of LLM purposes with updatable context. The connector makes it straightforward to replace the LLM context by loading, chunking, producing embeddings, and inserting them into the Pinecone database as quickly as new information is obtainable.
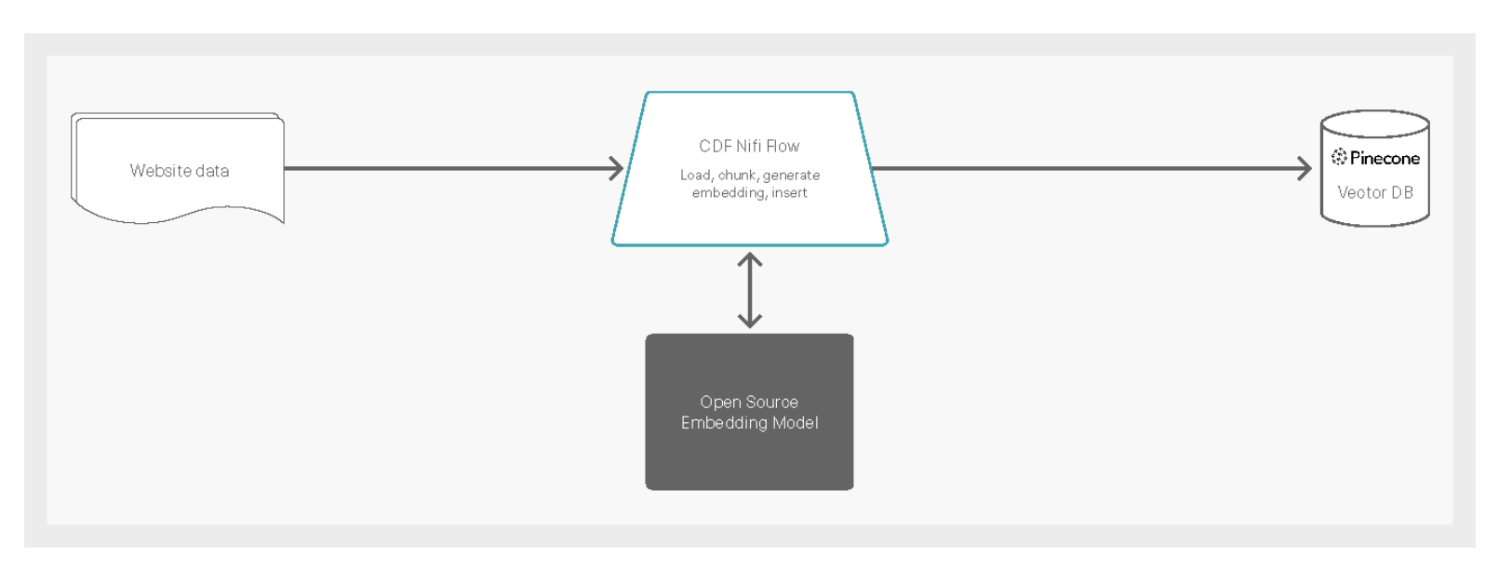
Fig 1. Excessive-level overview of real-time information ingest with Cloudera DataFlow to Pinecone vector database.
Navigating the problem of “hallucinations”
Our latest AMP is engineered to deal with a prevalent problem within the deployment of generative AI options: “hallucinations.” The AMP demonstrates how organizations can create a dynamic information base from web site information, enhancing the chatbot’s capability to ship context-rich, correct responses. Its structure, referred to as retrieval-augmented technology (RAG), is vital in decreasing hallucinated responses, enhancing the reliability and utility of LLM purposes, making person expertise extra significant and priceless.
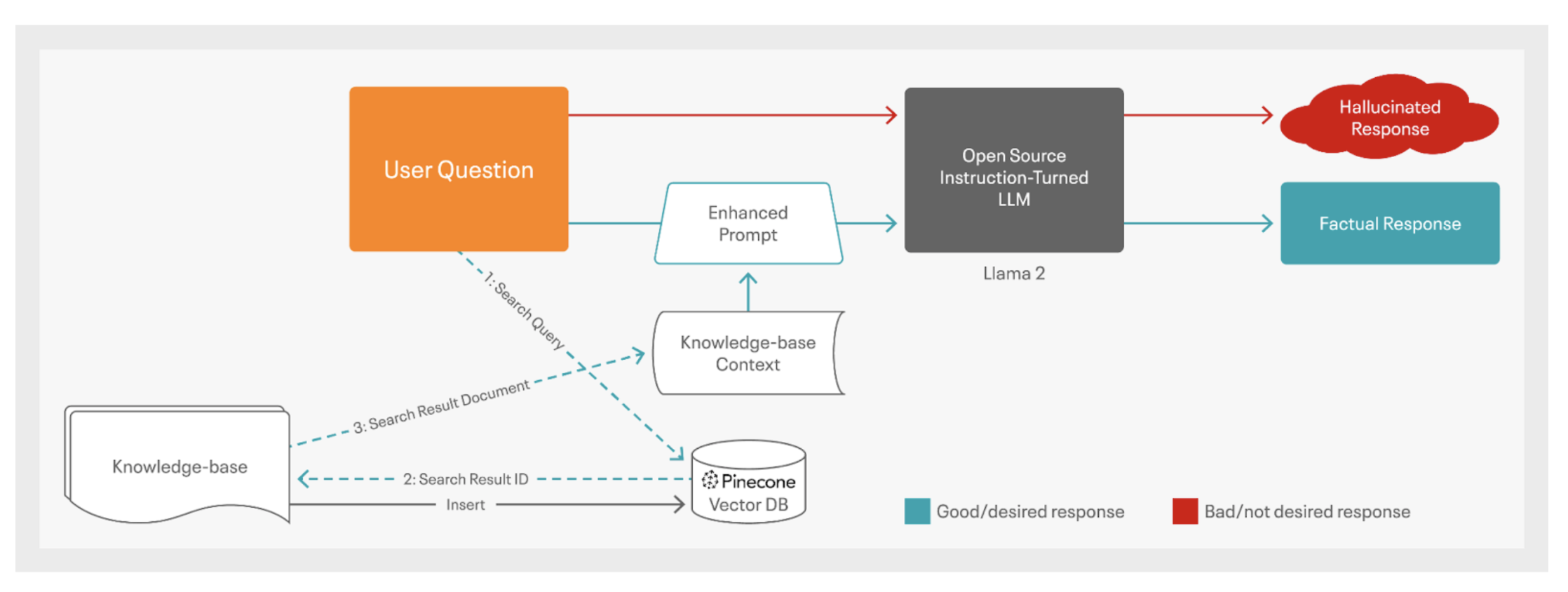
Fig 2. An outline of the RAG structure with a vector database used to attenuate hallucinations within the chatbot utility.
The Pinecone benefit
Pinecone’s vector database emerges as a pivotal asset, appearing because the long-term reminiscence for AI, important for imbuing interactions with context and accuracy. Using Pinecone’s expertise with Cloudera creates an ecosystem that facilitates the creation and deployment of strong, scalable, real-time AI purposes fueled by a corporation’s distinctive high-value information. Managing the information that represents organizational information is straightforward for any developer and doesn’t require exhaustive cycles of information science work.
Using Pinecone for vector information storage over an in-house open-source vector retailer generally is a prudent selection for organizations. Pinecone alleviates the operational burden of managing and scaling a vector database, permitting groups to focus extra on deriving insights from information. It provides a extremely optimized atmosphere for similarity search and personalization, with a devoted staff guaranteeing continuous service enhancement. Conversely, self-managed options might demand vital time and sources to keep up and optimize, making Pinecone a extra environment friendly and dependable selection.
Embrace the brand new capabilities
Our new LLM chatbot AMP, enhanced by Pinecone’s vector database and real-time embedding ingestion, is a testomony to our dedication to pushing the boundaries in utilized machine studying. It embodies our dedication to offering refined, progressive, and sensible options that meet the evolving calls for and challenges within the discipline of AI and machine studying. We invite you to discover the improved functionalities of this newest AMP.
[ad_2]