
[ad_1]
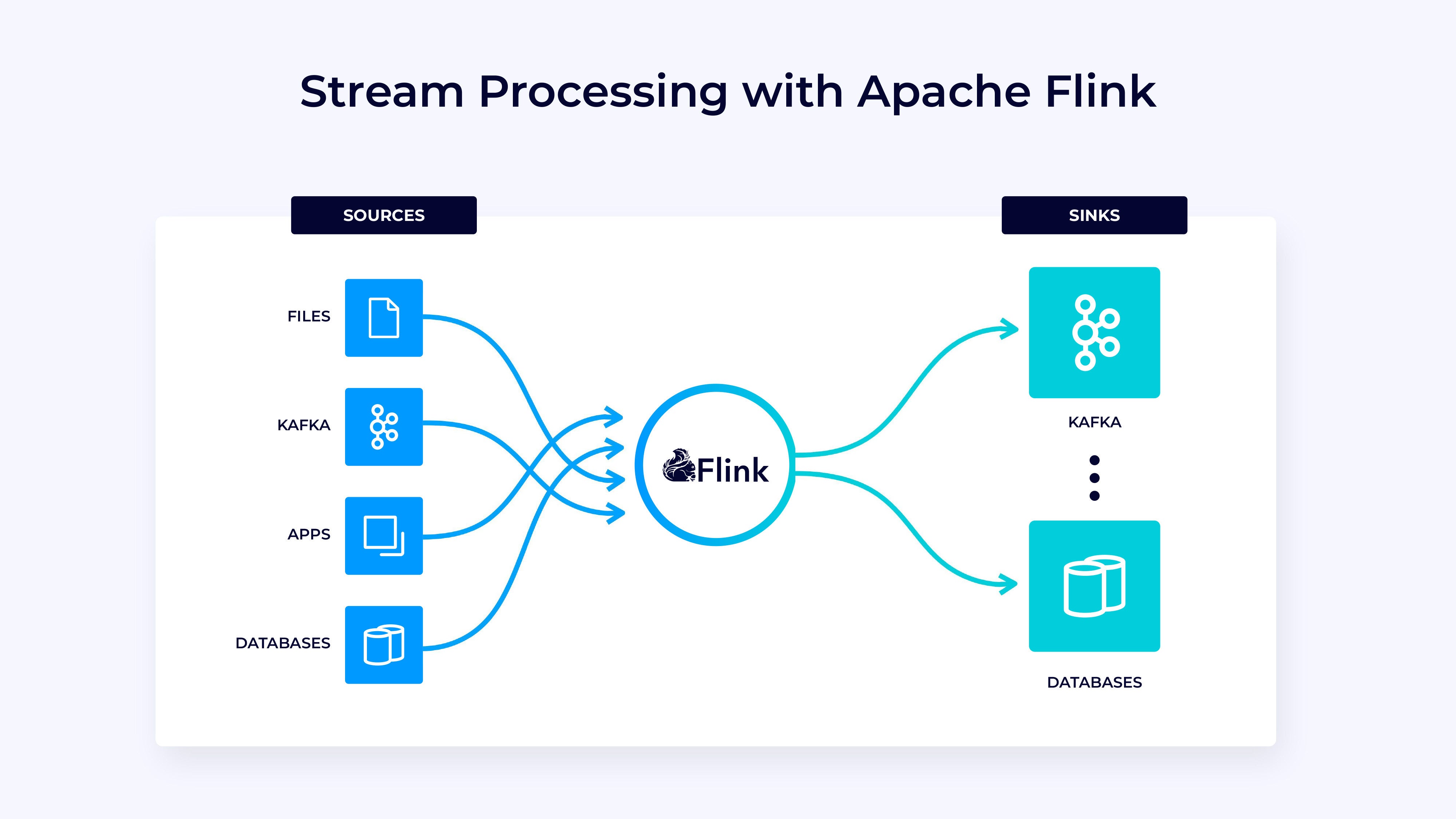
Lately, Apache Flink has established itself because the de facto normal for real-time stream processing. Stream processing is a paradigm for system constructing that treats occasion streams (sequences of occasions in time) as its most important constructing block. A stream processor, comparable to Flink, consumes enter streams produced by occasion sources, and produces output streams which can be consumed by sinks. The sinks retailer outcomes and make them accessible for additional processing.
Family names like Amazon, Netflix, and Uber depend on Flink to energy information pipelines operating at great scale on the coronary heart of their companies. However Flink additionally performs a key function in lots of smaller firms with comparable necessities for with the ability to react rapidly to essential enterprise occasions.
 IDG
IDGWhat’s Flink getting used for? Widespread use circumstances fall into three classes.
|
Streaming information pipelines |
Actual-time analytics |
Occasion-driven functions |
|
Repeatedly ingest, enrich, and rework information streams, loading them into vacation spot techniques for well timed motion (vs. batch processing). |
Repeatedly produce and replace outcomes that are displayed and delivered to customers as real-time information streams are consumed. |
Acknowledge patterns and react to incoming occasions by triggering computations, state updates, or exterior actions. |
|
Some examples embrace:
|
Some examples embrace:
|
Some examples embrace:
|
And what makes Flink particular?
- Sturdy help for information streaming workloads on the scale wanted by world enterprises.
- Sturdy ensures of exactly-once correctness and failure restoration.
- Assist for Java, Python, and SQL, with unified help for each batch and stream processing.
- Flink is a mature open-source mission from the Apache Software program Basis and has a really energetic and supportive neighborhood.
Flink is typically described as being advanced and troublesome to study. Sure, the implementation of Flink’s runtime is advanced, however that shouldn’t be stunning, because it solves some troublesome issues. Flink APIs could be considerably difficult to study, however this has extra to do with the ideas and organizing ideas being unfamiliar than with any inherent complexity.
Flink could also be totally different from something you’ve used earlier than, however in lots of respects it’s really moderately easy. Sooner or later, as you turn into extra aware of the way in which that Flink is put collectively, and the problems that its runtime should tackle, the small print of Flink’s APIs ought to start to strike you as being the apparent penalties of some key ideas, moderately than a set of arcane particulars you must memorize.
This text goals to make the Flink studying journey a lot simpler, by laying out the core ideas underlying its design.
Flink embodies a couple of huge concepts
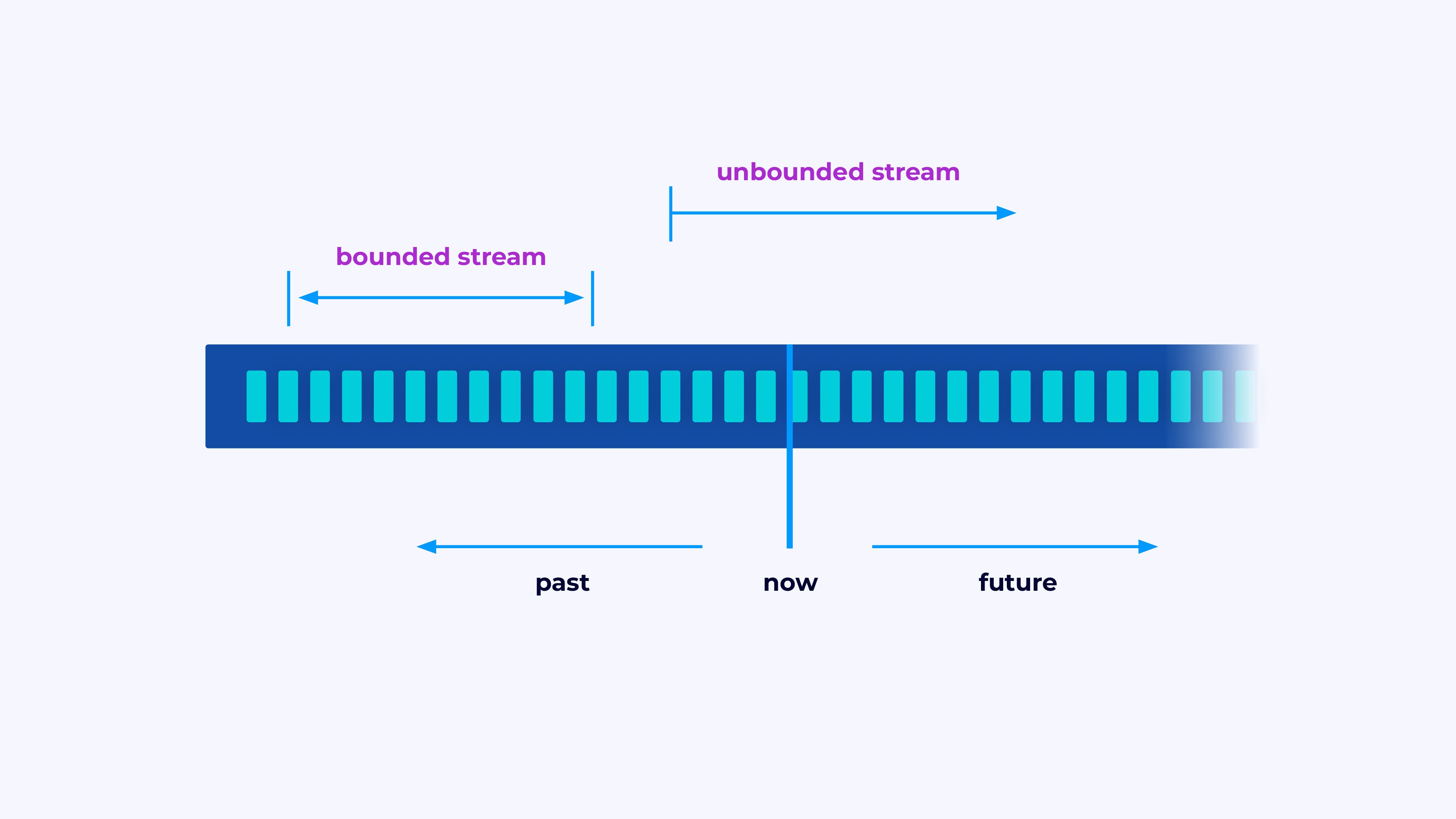
Streams
Flink is a framework for constructing functions that course of occasion streams, the place a stream is a bounded or unbounded sequence of occasions.
 IDG
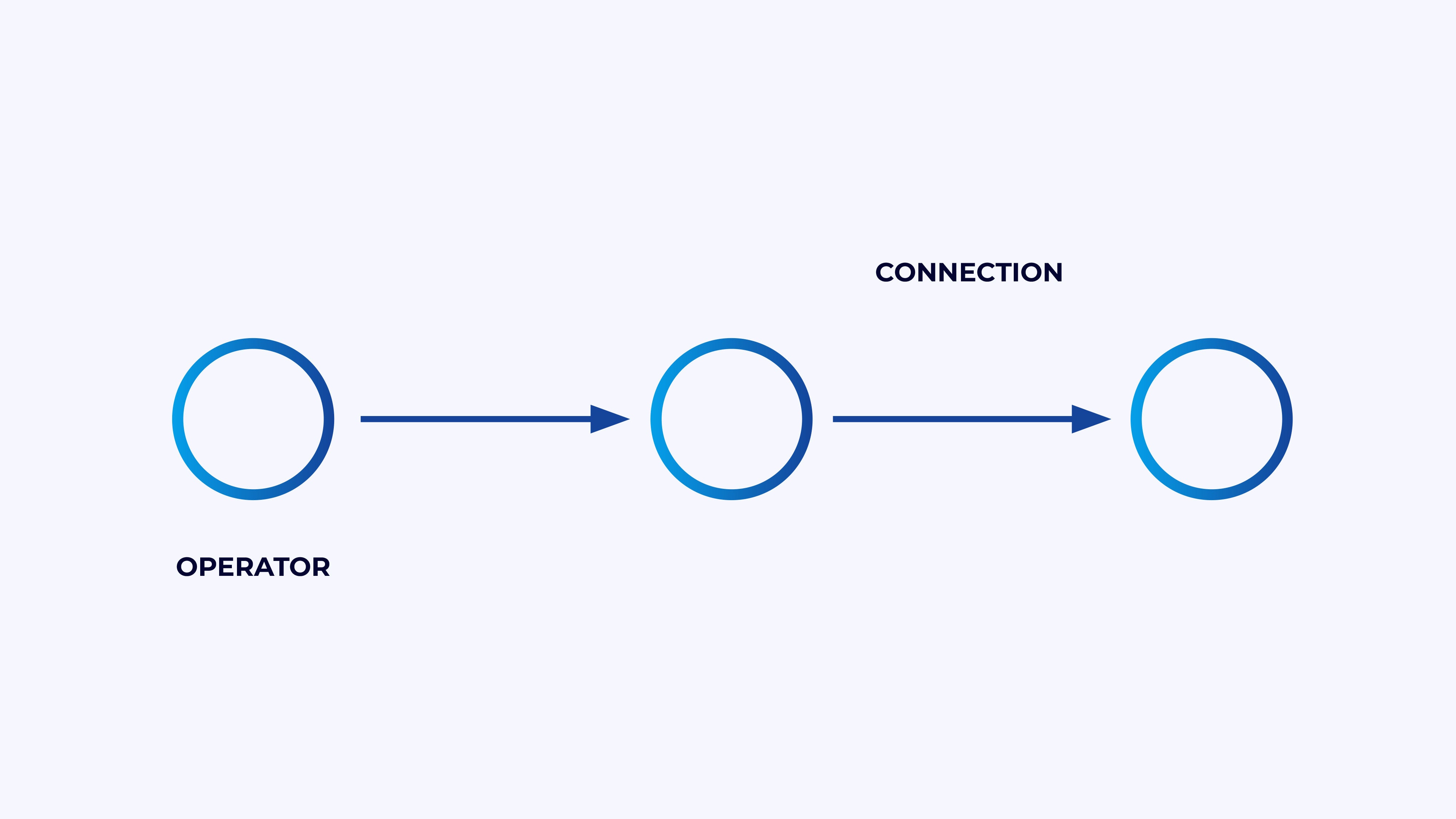
IDGA Flink software is an information processing pipeline. Your occasions stream by this pipeline, and they’re operated on at every stage by code you write. We name this pipeline the job graph, and the nodes of this graph (or in different phrases, the levels of the processing pipeline) are referred to as operators.
 IDG
IDGThe code you write utilizing one in every of Flink’s APIs describes the job graph, together with the habits of the operators and their connections.
Parallel processing
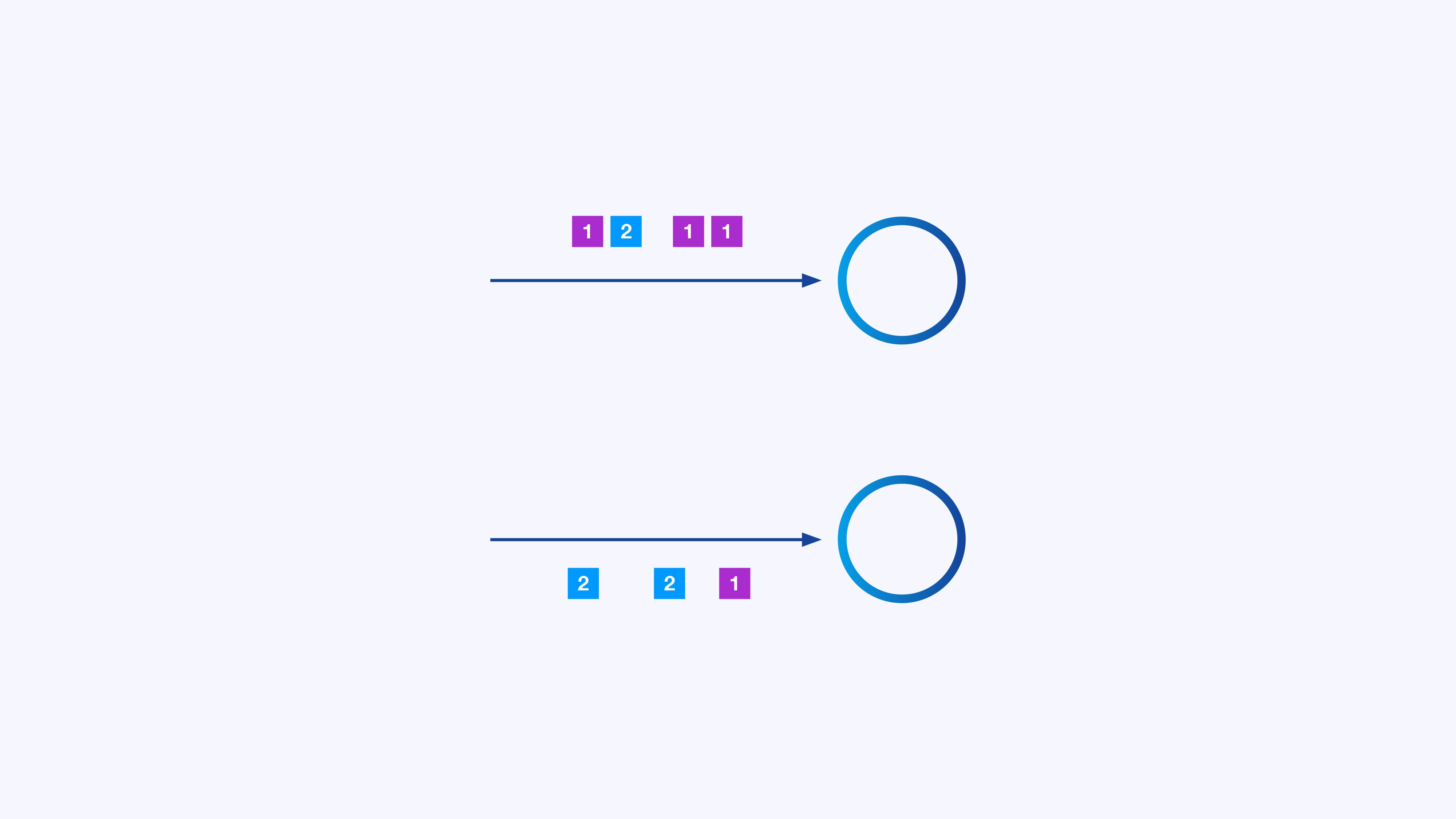
Every operator can have many parallel cases, every working independently on some subset of the occasions.
 IDG
IDGGenerally you’ll want to impose a selected partitioning scheme on these sub-streams, in order that the occasions are grouped collectively in line with some application-specific logic. For instance, in case you’re processing monetary transactions, you may want each occasion for any given transaction to be processed by the identical thread. It will let you join collectively the assorted occasions that happen over time for every transaction.
In Flink SQL you’d do that with GROUP BY transaction_id, whereas within the DataStream API you’d use keyBy(occasion -> occasion.transaction_id) to specify this grouping, or partitioning. In both case, this may present up within the job graph as a totally related community shuffle between two consecutive levels of the graph.
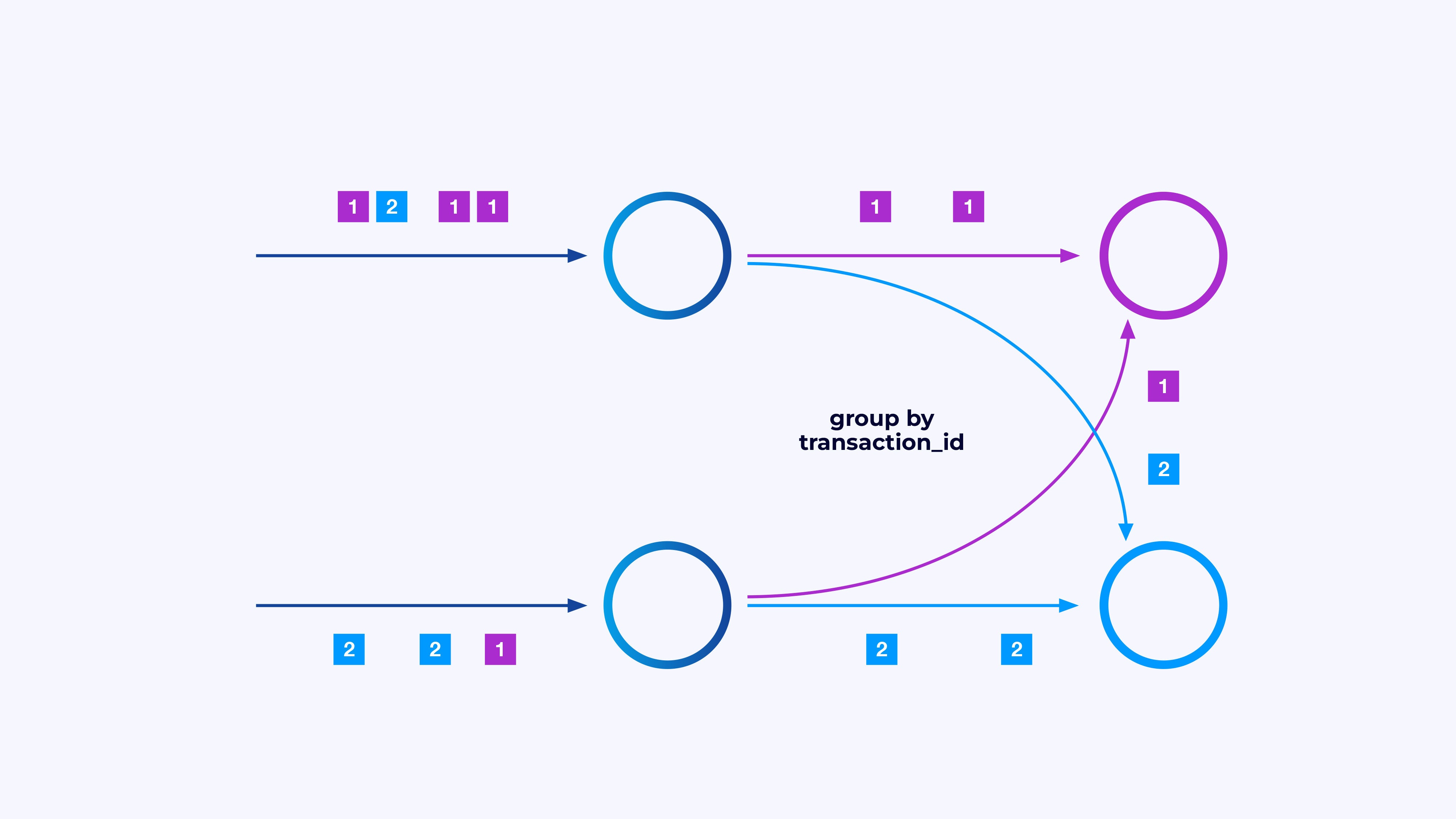 IDG
IDGState
Operators engaged on key-partitioned streams can use Flink’s distributed key/worth state retailer to durably persist no matter they need. The state for every secret is native to a selected occasion of an operator, and can’t be accessed from anyplace else. The parallel sub-topologies share nothing—that is essential for unrestrained scalability.
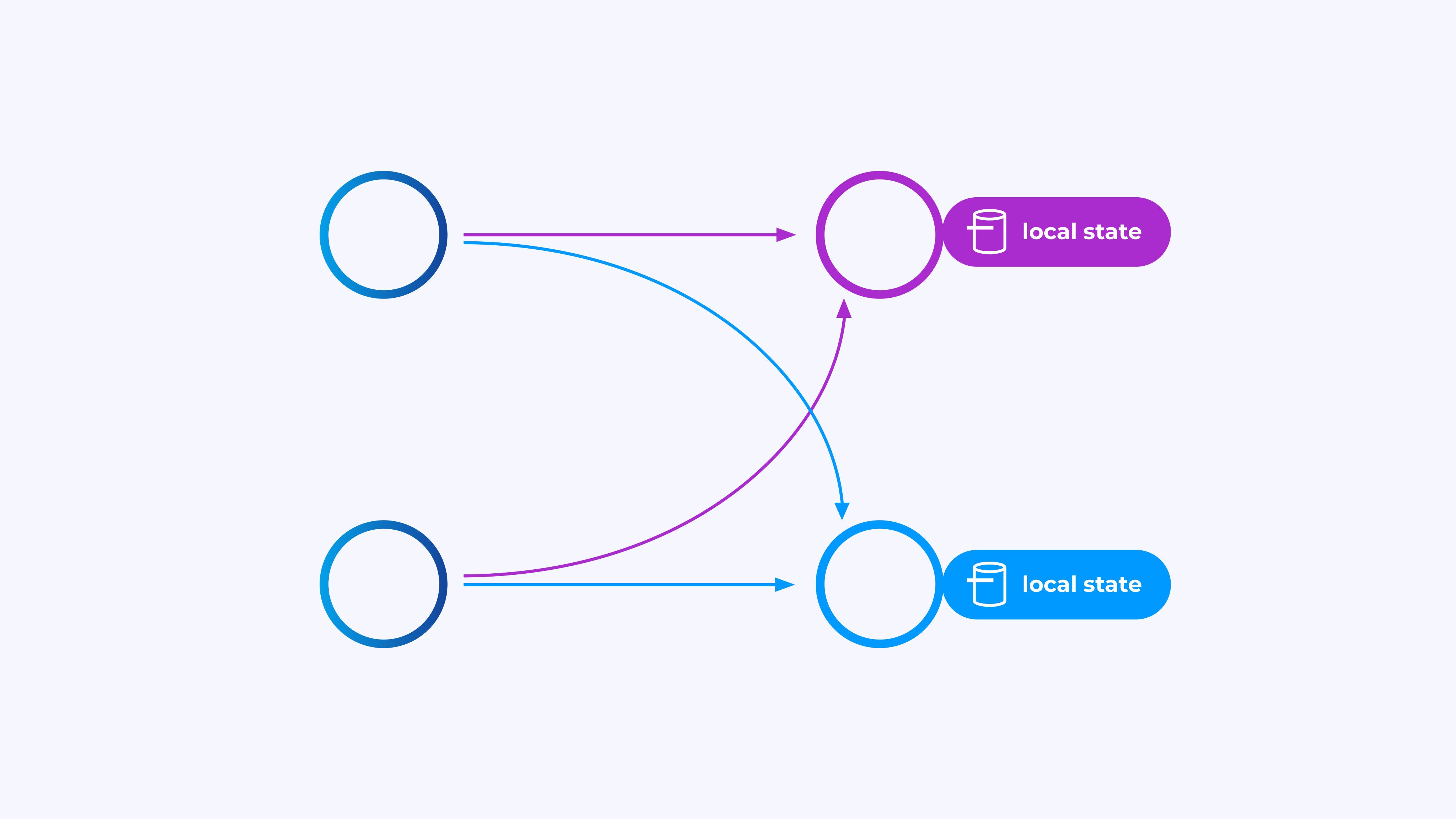 IDG
IDGA Flink job is perhaps left operating indefinitely. If a Flink job is repeatedly creating new keys (e.g., transaction IDs) and storing one thing for every new key, then that job dangers blowing up as a result of it’s utilizing an unbounded quantity of state. Every of Flink’s APIs is organized round offering methods that can assist you keep away from runaway explosions of state.
Time
One technique to keep away from hanging onto state for too lengthy is to retain it solely till some particular cut-off date. For example, if you wish to rely transactions in minute-long home windows, as soon as every minute is over, the end result for that minute could be produced, and that counter could be freed.
Flink makes an vital distinction between two totally different notions of time:
- Processing (or wall clock) time, which is derived from the precise time of day when an occasion is being processed.
- Occasion time, which is predicated on timestamps recorded with every occasion.
As an example the distinction between them, take into account what it means for a minute-long window to be full:
- A processing time window is full when the minute is over. That is completely easy.
- An occasion time window is full when all occasions that occurred throughout that minute have been processed. This may be tough, since Flink can’t know something about occasions it hasn’t processed but. The very best we are able to do is to make an assumption about how out-of-order a stream is perhaps, and apply that assumption heuristically.
Checkpointing for failure restoration
Failures are inevitable. Regardless of failures, Flink is ready to present successfully exactly-once ensures, which means that every occasion will have an effect on the state Flink is managing precisely as soon as, simply as if the failure by no means occurred. It does this by taking periodic, world, self-consistent snapshots of all of the state. These snapshots, created and managed routinely by Flink, are referred to as checkpoints.
Restoration includes rolling again to the state captured in the latest checkpoint, and performing a world restart of all the operators from that checkpoint. Throughout restoration some occasions are reprocessed, however Flink is ready to assure correctness by making certain that every checkpoint is a world, self-consistent snapshot of the entire state of the system.
Flink system structure
Flink functions run in Flink clusters, so earlier than you’ll be able to put a Flink software into manufacturing, you’ll want a cluster to deploy it to. Happily, throughout improvement and testing it’s simple to get began by operating Flink domestically in an built-in improvement setting like JetBrains IntelliJ, or in Docker.
A Flink cluster has two sorts of parts: a job supervisor and a set of activity managers. The duty managers run your functions (in parallel), whereas the job supervisor acts as a gateway between the duty managers and the skin world. Purposes are submitted to the job supervisor, which manages the sources supplied by the duty managers, coordinates checkpointing, and supplies visibility into the cluster within the type of metrics.
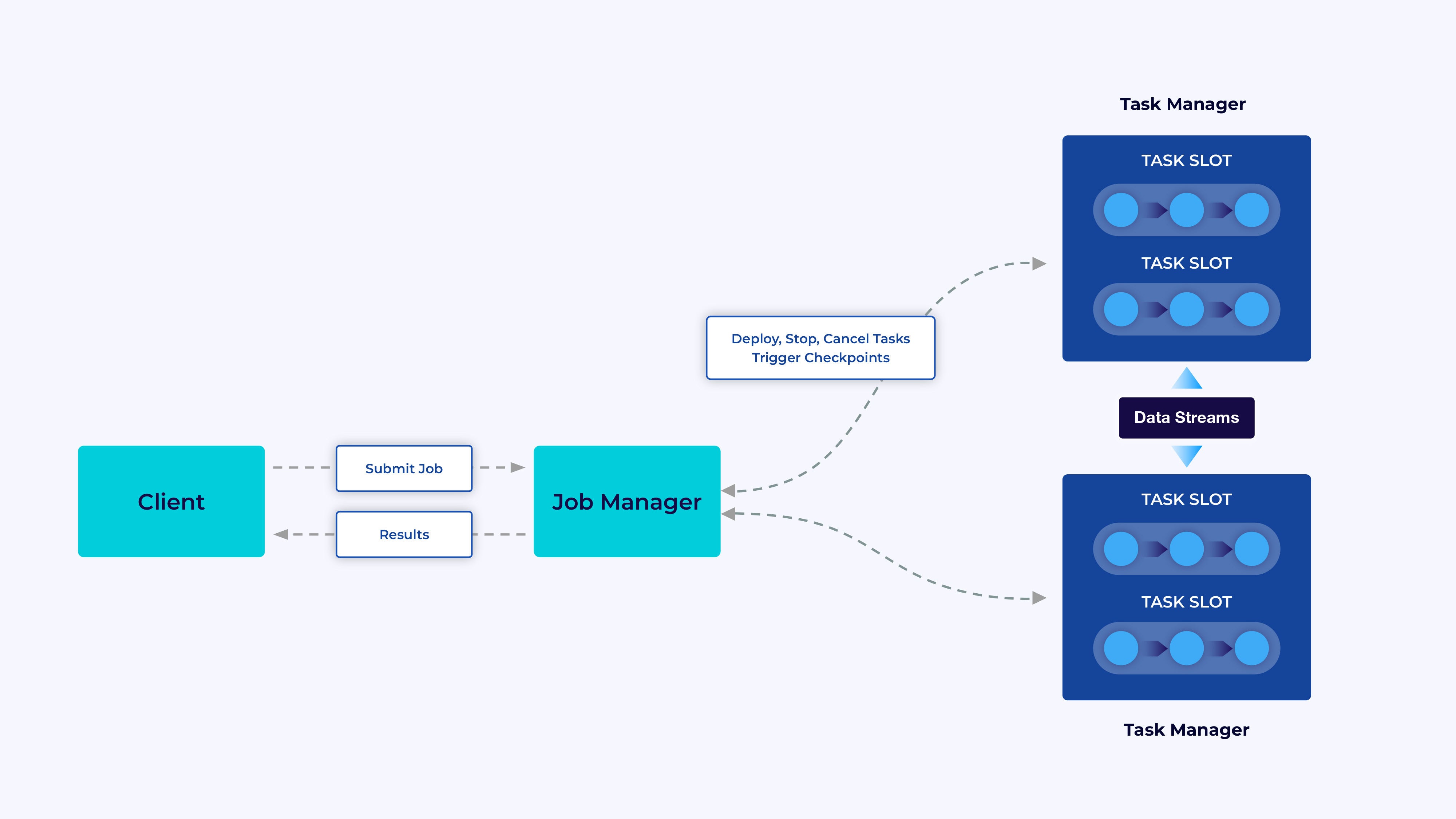 IDG
IDGFlink developer expertise
The expertise you’ll have as a Flink developer relies upon, to a sure extent, on which of the APIs you select: both the older, lower-level DataStream API or the newer, relational Desk and SQL APIs.
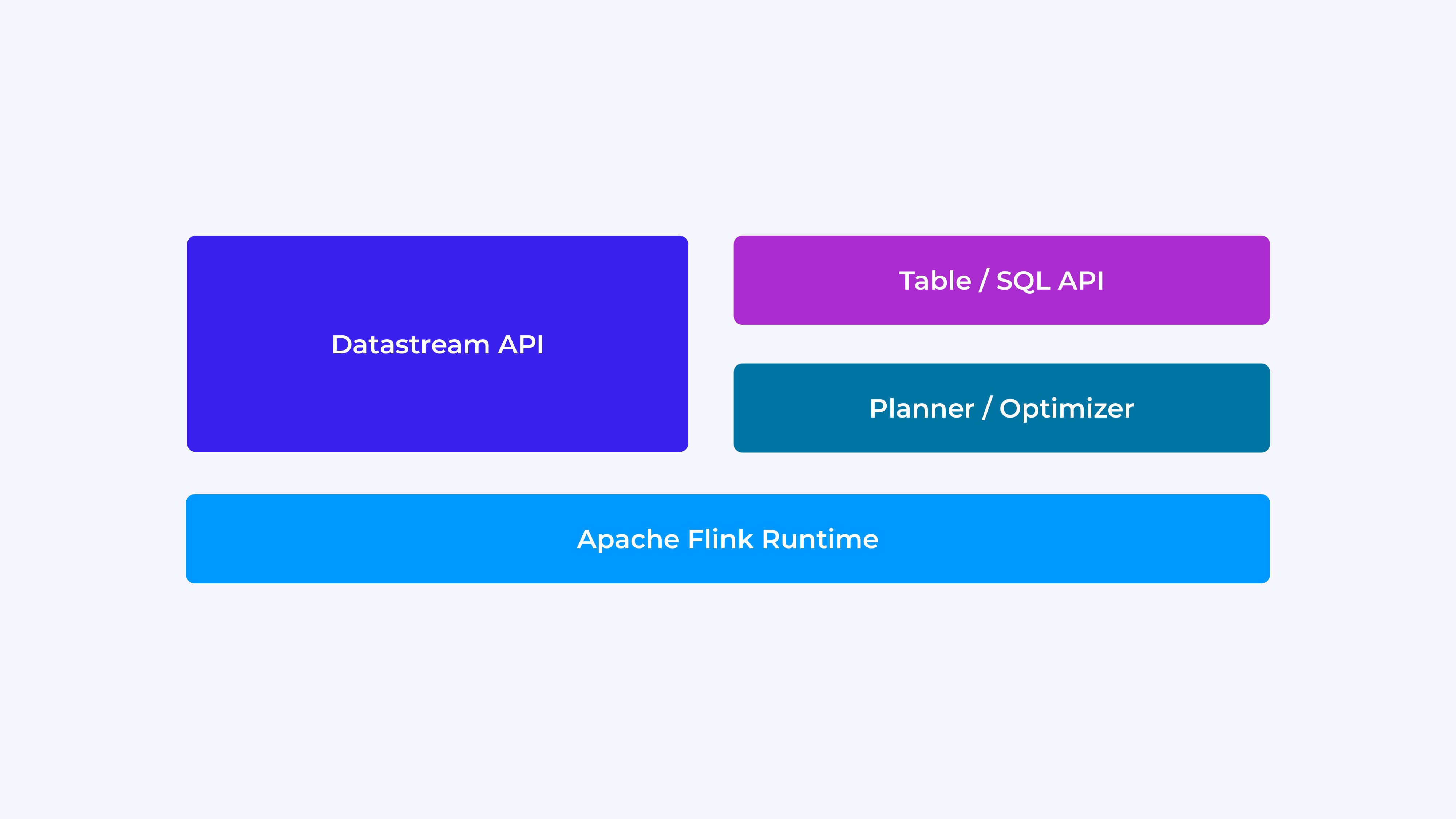 IDG
IDGIf you find yourself programming with Flink’s DataStream API, you’re consciously fascinated about what the Flink runtime shall be doing because it runs your software. Which means you’re build up the job graph one operator at a time, describing the state you’re utilizing together with the kinds concerned and their serialization, creating timers and implementing callback features to be executed when these timers are triggered, and many others. The core abstraction within the DataStream API is the occasion, and the features you write shall be dealing with one occasion at a time, as they arrive.
Alternatively, whenever you use Flink’s Desk/SQL API, these low-level considerations are taken care of for you, and you’ll focus extra straight on what you are promoting logic. The core abstraction is the desk, and you’re considering extra when it comes to becoming a member of tables for enrichment, grouping rows collectively to compute aggregated analytics, and many others. A built-in SQL question planner/optimizer takes care of the small print. The planner/optimizer does a wonderful job of managing sources effectively, usually out-performing hand-written code.
A pair extra ideas earlier than diving into the small print: First, you don’t have to decide on the DataStream or the Desk/SQL API—each APIs are interoperable, and you’ll mix them. That may be a great way to go in case you want a little bit of customization that isn’t potential within the Desk/SQL API. Second, one other good technique to transcend what Desk/SQL API gives out of the field is so as to add some extra capabilities within the type of user-defined features (UDFs). Right here, Flink SQL gives loads of choices for extension.
Establishing the job graph
No matter which API you utilize, the final word objective of the code you write is to assemble the job graph that Flink’s runtime will execute in your behalf. Which means these APIs are organized round creating operators and specifying each their habits and their connections to at least one one other. With the DataStream API you’re straight setting up the job graph. With the Desk/SQL API, Flink’s SQL planner is taking good care of this.
Serializing features and information
In the end, the code you provide to Flink shall be executed in parallel by the employees (the duty managers) in a Flink cluster. To make this occur, the perform objects you create are serialized and despatched to the duty managers the place they’re executed. Equally, the occasions themselves will typically have to be serialized and despatched throughout the community from one activity supervisor to a different. Once more, with the Desk/SQL API you don’t have to consider this.
Managing state
The Flink runtime must be made conscious of any state that you just anticipate it to get well for you within the occasion of a failure. To make this work, Flink wants sort info it could possibly use to serialize and deserialize these objects (to allow them to be written into, and skim from, checkpoints). You’ll be able to optionally configure this managed state with time-to-live descriptors that Flink will then use to routinely expire state as soon as it has outlived its usefulness.
With the DataStream API you usually find yourself straight managing the state your software wants (the built-in window operations are the one exception to this). Alternatively, with the Desk/SQL API this concern is abstracted away. For instance, given a question just like the one under, you recognize that someplace within the Flink runtime some information construction must be sustaining a counter for every URL, however the particulars are all taken care of for you.
SELECT url, COUNT(*) FROM pageviews GROUP BY url;
Setting and triggering timers
Timers have many makes use of in stream processing. For instance, it is not uncommon for Flink functions to wish to assemble info from many various occasion sources earlier than finally producing outcomes. Timers work properly for circumstances the place it is sensible to attend (however not indefinitely) for information which will (or might not) finally arrive.
Timers are additionally important for implementing time-based windowing operations. Each the DataStream and Desk/SQL APIs have built-in help for home windows, and they’re creating and managing timers in your behalf.
Flink use circumstances
Circling again to the three broad classes of streaming use circumstances launched at the start of this text, let’s see how they map onto what you’ve simply been studying about Flink.
Streaming information pipelines
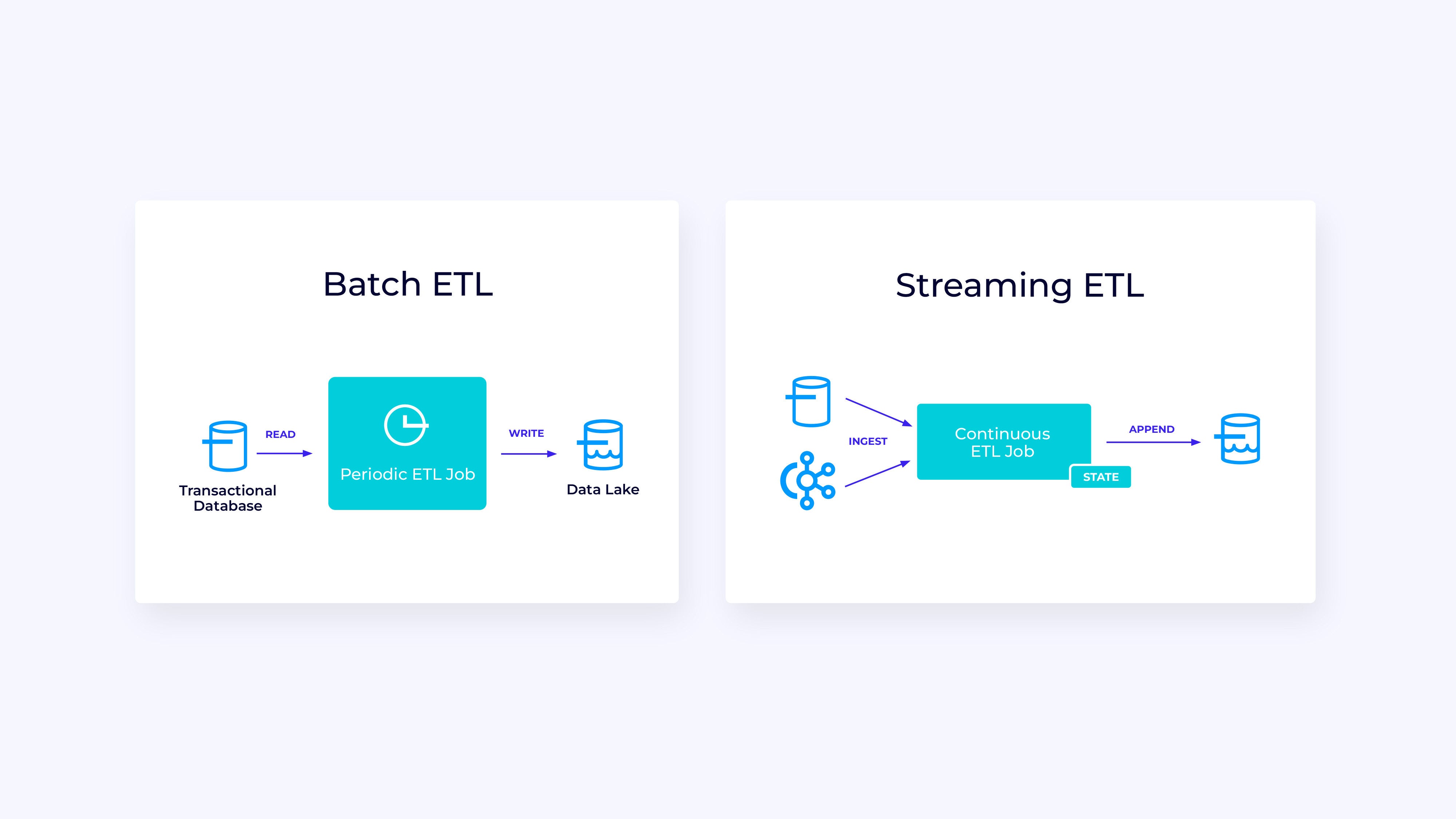
Under, at left, is an instance of a standard batch ETL (extract, rework, and cargo) job that periodically reads from a transactional database, transforms the information, and writes the outcomes out to a different information retailer, comparable to a database, file system, or information lake.
 IDG
IDGThe corresponding streaming pipeline is superficially comparable, however has some vital variations:
- The streaming pipeline is at all times operating.
- The transactional information is being delivered to the streaming pipeline in two components: an preliminary bulk load from the database and a change information seize (CDC) stream that delivers the database updates since that bulk load.
- The streaming model repeatedly produces new outcomes as quickly as they turn into accessible.
- State is explicitly managed in order that it may be robustly recovered within the occasion of a failure. Streaming ETL pipelines usually use little or no state. The information sources maintain observe of precisely how a lot of the enter has been ingested, usually within the type of offsets that rely information for the reason that starting of the streams. The sinks use transactions to handle their writes to exterior techniques, like databases or Apache Kafka. Throughout checkpointing, the sources file their offsets, and the sinks commit the transactions that carry the outcomes of getting learn precisely as much as, however not past, these supply offsets.
For this use case, the Desk/SQL API can be a good selection.
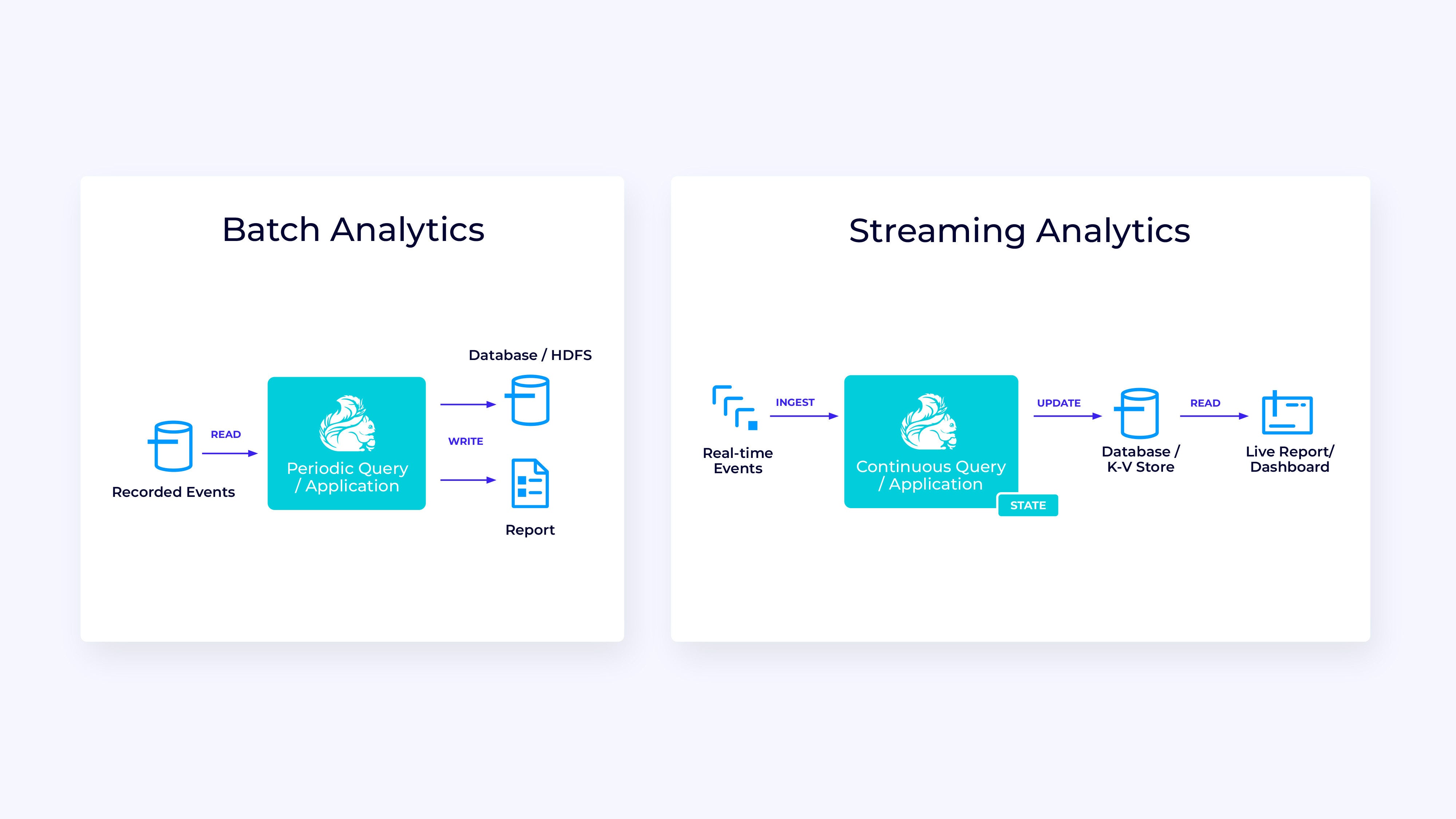
Actual-time analytics
In comparison with the streaming ETL software, the streaming analytics software has a few fascinating variations:
- As with streaming ETL, Flink is getting used to run a steady software, however for this software Flink will in all probability have to handle considerably extra state.
- For this use case it is sensible for the stream being ingested to be saved in a stream-native storage system, comparable to Kafka.
- Fairly than periodically producing a static report, the streaming model can be utilized to drive a reside dashboard.
As soon as once more, the Desk/SQL API is often a good selection for this use case.
 IDG
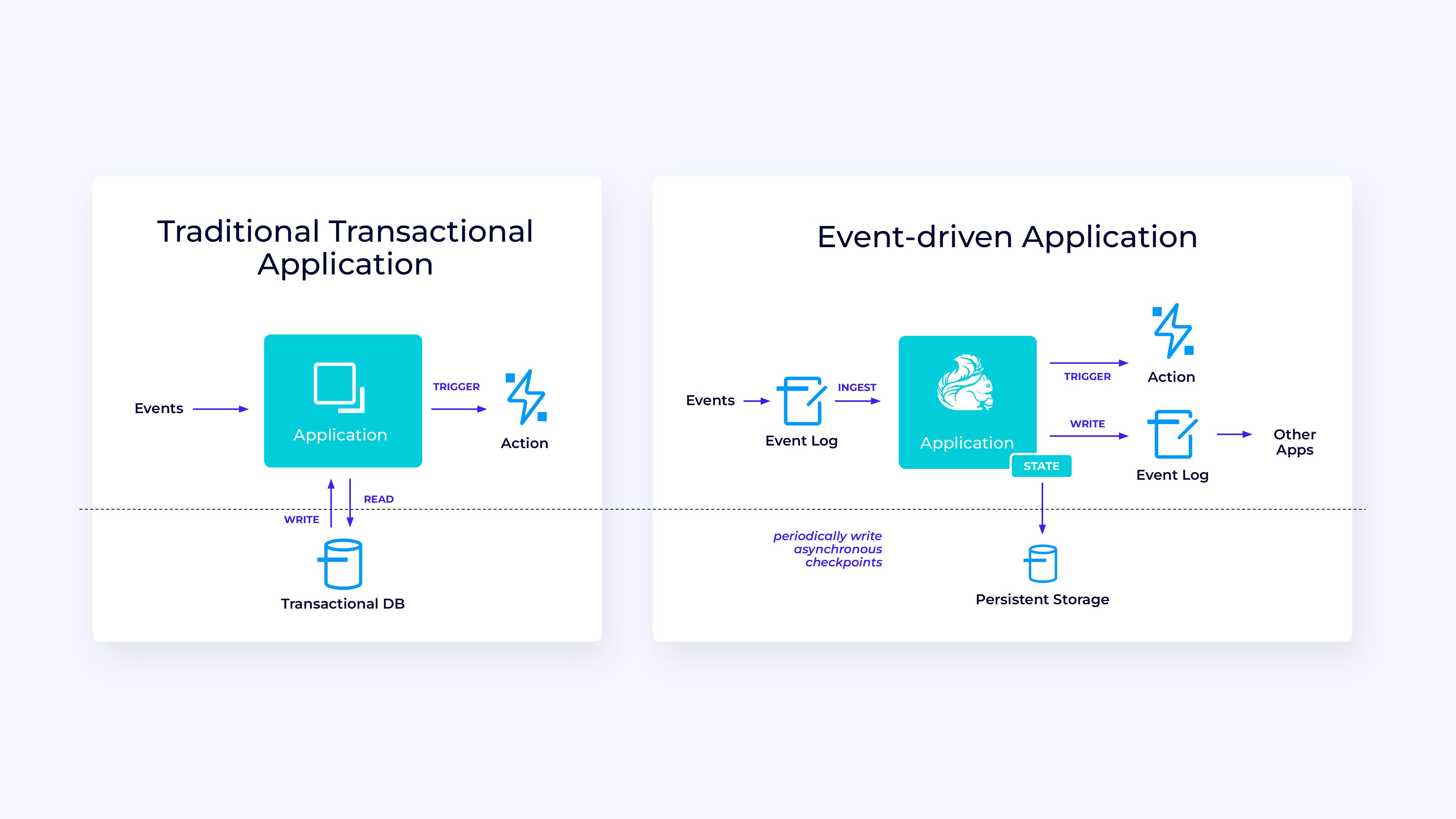
IDGOccasion-driven functions
Our third and last household of use circumstances includes the implementation of event-driven functions or microservices. A lot has been written on this subject; that is an architectural design sample that has loads of advantages.
 IDG
IDGFlink is usually a nice match for these functions, particularly in case you want the type of efficiency Flink can ship. In some circumstances the Desk/SQL API has every little thing you want, however in lots of circumstances you’ll want the extra flexibility of the DataStream API for no less than a part of the job.
Get began with Flink immediately
Flink supplies a robust framework for constructing functions that course of occasion streams. A few of the ideas could seem novel at first, however when you’re aware of the way in which Flink is designed and the way it operates, the software program is intuitive to make use of and the rewards of figuring out Flink are vital.
As a subsequent step, comply with the directions within the Flink documentation, which can information you thru the method of downloading, putting in, and operating the most recent secure model of Flink. Take into consideration the broad use circumstances we mentioned—trendy information pipelines, real-time analytics, and event-driven microservices—and the way these might help to handle a problem or drive worth in your group.
Information streaming is likely one of the most enjoyable areas of enterprise expertise immediately, and stream processing with Flink makes it much more highly effective. Studying Flink shall be helpful in your group, but additionally in your profession, as a result of real-time information processing is changing into extra worthwhile to companies globally. So take a look at Flink immediately and see what this highly effective expertise might help you obtain.
David Anderson is software program apply lead at Confluent.
—
New Tech Discussion board supplies a venue for expertise leaders—together with distributors and different exterior contributors—to discover and focus on rising enterprise expertise in unprecedented depth and breadth. The choice is subjective, primarily based on our choose of the applied sciences we imagine to be vital and of biggest curiosity to InfoWorld readers. InfoWorld doesn’t settle for advertising and marketing collateral for publication and reserves the best to edit all contributed content material. Ship all inquiries to [email protected].
Copyright © 2023 IDG Communications, Inc.
[ad_2]