
[ad_1]

|
I’m excited to announce at the moment a brand new functionality of Amazon Managed Streaming for Apache Kafka (Amazon MSK) that permits you to constantly load information from an Apache Kafka cluster to Amazon Easy Storage Service (Amazon S3). We use Amazon Kinesis Knowledge Firehose—an extract, remodel, and cargo (ETL) service—to learn information from a Kafka subject, remodel the information, and write them to an Amazon S3 vacation spot. Kinesis Knowledge Firehose is totally managed and you’ll configure it with only a few clicks within the console. No code or infrastructure is required.
Kafka is often used for constructing real-time information pipelines that reliably transfer large quantities of information between methods or purposes. It gives a extremely scalable and fault-tolerant publish-subscribe messaging system. Many AWS clients have adopted Kafka to seize streaming information corresponding to click-stream occasions, transactions, IoT occasions, and software and machine logs, and have purposes that carry out real-time analytics, run steady transformations, and distribute this information to information lakes and databases in actual time.
Nonetheless, deploying Kafka clusters shouldn’t be with out challenges.
The primary problem is to deploy, configure, and keep the Kafka cluster itself. This is the reason we launched Amazon MSK in Might 2019. MSK reduces the work wanted to arrange, scale, and handle Apache Kafka in manufacturing. We care for the infrastructure, liberating you to focus in your information and purposes. The second problem is to jot down, deploy, and handle software code that consumes information from Kafka. It sometimes requires coding connectors utilizing the Kafka Join framework after which deploying, managing, and sustaining a scalable infrastructure to run the connectors. Along with the infrastructure, you additionally should code the info transformation and compression logic, handle the eventual errors, and code the retry logic to make sure no information is misplaced throughout the switch out of Kafka.
Right now, we announce the supply of a completely managed answer to ship information from Amazon MSK to Amazon S3 utilizing Amazon Kinesis Knowledge Firehose. The answer is serverless–there isn’t any server infrastructure to handle–and requires no code. The information transformation and error-handling logic might be configured with just a few clicks within the console.
The structure of the answer is illustrated by the next diagram.

Amazon MSK is the info supply, and Amazon S3 is the info vacation spot whereas Amazon Kinesis Knowledge Firehose manages the info switch logic.
When utilizing this new functionality, you not must develop code to learn your information from Amazon MSK, remodel it, and write the ensuing information to Amazon S3. Kinesis Knowledge Firehose manages the studying, the transformation and compression, and the write operations to Amazon S3. It additionally handles the error and retry logic in case one thing goes unsuitable. The system delivers the information that may not be processed to the S3 bucket of your selection for handbook inspection. The system additionally manages the infrastructure required to deal with the info stream. It can scale out and scale in robotically to regulate to the quantity of information to switch. There are not any provisioning or upkeep operations required in your facet.
Kinesis Knowledge Firehose supply streams help each private and non-private Amazon MSK provisioned or serverless clusters. It additionally helps cross-account connections to learn from an MSK cluster and to jot down to S3 buckets in several AWS accounts. The Knowledge Firehose supply stream reads information out of your MSK cluster, buffers the info for a configurable threshold measurement and time, after which writes the buffered information to Amazon S3 as a single file. MSK and Knowledge Firehose have to be in the identical AWS Area, however Knowledge Firehose can ship information to Amazon S3 buckets in different Areas.
Kinesis Knowledge Firehose supply streams also can convert information sorts. It has built-in transformations to help JSON to Apache Parquet and Apache ORC codecs. These are columnar information codecs that save area and allow quicker queries on Amazon S3. For non-JSON information, you should use AWS Lambda to rework enter codecs corresponding to CSV, XML, or structured textual content into JSON earlier than changing the info to Apache Parquet/ORC. Moreover, you possibly can specify information compression codecs from Knowledge Firehose, corresponding to GZIP, ZIP, and SNAPPY, earlier than delivering the info to Amazon S3, or you possibly can ship the info to Amazon S3 in its uncooked type.
Let’s See How It Works
To get began, I exploit an AWS account the place there’s an Amazon MSK cluster already configured and a few purposes streaming information to it. To get began and to create your first Amazon MSK cluster, I encourage you to learn the tutorial.
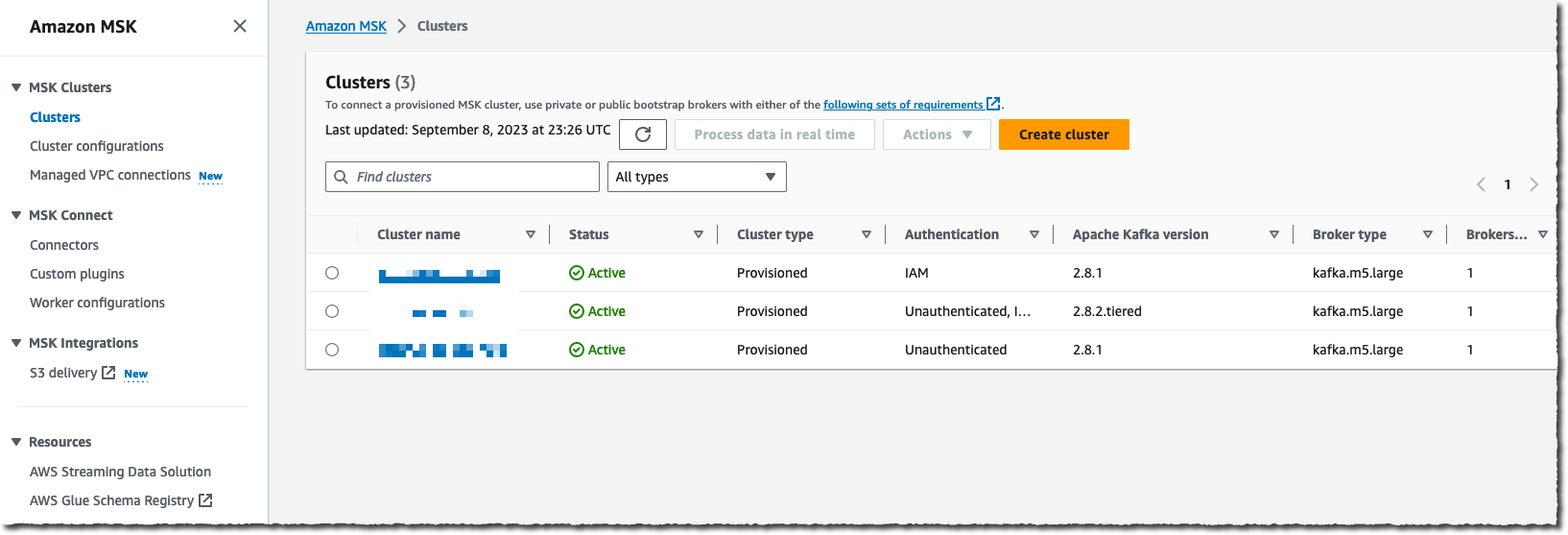
For this demo, I exploit the console to create and configure the info supply stream. Alternatively, I can use the AWS Command Line Interface (AWS CLI), AWS SDKs, AWS CloudFormation, or Terraform.
I navigate to the Amazon Kinesis Knowledge Firehose web page of the AWS Administration Console after which select Create supply stream.
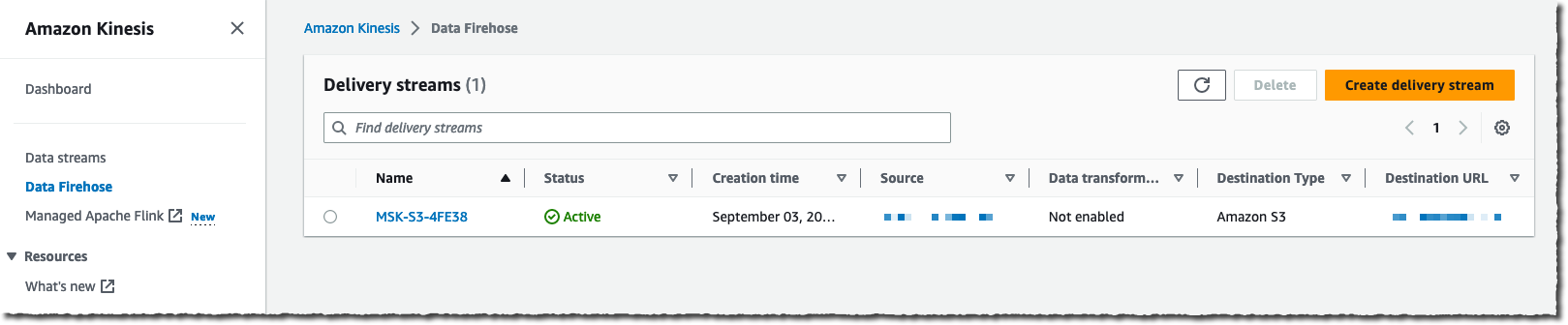
I choose Amazon MSK as an information Supply and Amazon S3 as a supply Vacation spot. For this demo, I wish to connect with a non-public cluster, so I choose Personal bootstrap brokers below Amazon MSK cluster connectivity.
I must enter the total ARN of my cluster. Like most individuals, I can not keep in mind the ARN, so I select Browse and choose my cluster from the checklist.
Lastly, I enter the cluster Subject identify I need this supply stream to learn from.

After the supply is configured, I scroll down the web page to configure the info transformation part.
On the Remodel and convert information part, I can select whether or not I wish to present my very own Lambda operate to rework information that aren’t in JSON or to rework my supply JSON information to one of many two out there pre-built vacation spot information codecs: Apache Parquet or Apache ORC.
Apache Parquet and ORC codecs are extra environment friendly than JSON format to question information from Amazon S3. You possibly can choose these vacation spot information codecs when your supply information are in JSON format. You have to additionally present an information schema from a desk in AWS Glue.
These built-in transformations optimize your Amazon S3 value and scale back time-to-insights when downstream analytics queries are carried out with Amazon Athena, Amazon Redshift Spectrum, or different methods.

Lastly, I enter the identify of the vacation spot Amazon S3 bucket. Once more, after I can not keep in mind it, I exploit the Browse button to let the console information me by way of my checklist of buckets. Optionally, I enter an S3 bucket prefix for the file names. For this demo, I enter aws-news-blog. Once I don’t enter a prefix identify, Kinesis Knowledge Firehose makes use of the date and time (in UTC) because the default worth.
Beneath the Buffer hints, compression and encryption part, I can modify the default values for buffering, allow information compression, or choose the KMS key to encrypt the info at relaxation on Amazon S3.
When prepared, I select Create supply stream. After just a few moments, the stream standing adjustments to ✅ out there.

Assuming there’s an software streaming information to the cluster I selected as a supply, I can now navigate to my S3 bucket and see information showing within the chosen vacation spot format as Kinesis Knowledge Firehose streams it.
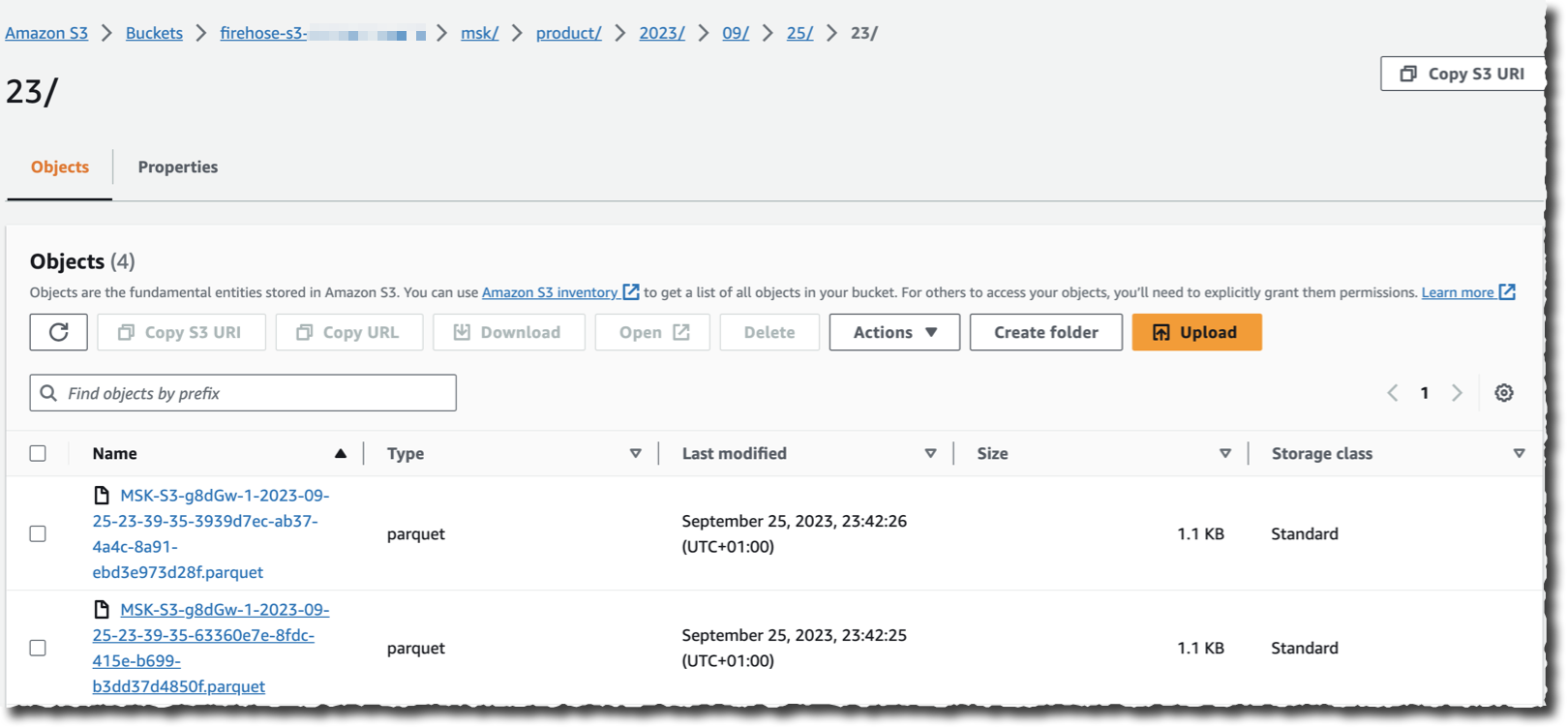
As you see, no code is required to learn, remodel, and write the information from my Kafka cluster. I additionally don’t need to handle the underlying infrastructure to run the streaming and transformation logic.
Pricing and Availability.
This new functionality is offered at the moment in all AWS Areas the place Amazon MSK and Kinesis Knowledge Firehose can be found.
You pay for the quantity of information going out of Amazon MSK, measured in GB monthly. The billing system takes into consideration the precise report measurement; there isn’t any rounding. As typical, the pricing web page has all the main points.
I can’t wait to listen to concerning the quantity of infrastructure and code you’re going to retire after adopting this new functionality. Now go and configure your first information stream between Amazon MSK and Amazon S3 at the moment.
[ad_2]