
[ad_1]
Many organizations that we’ve spoken to are within the exploration part of utilizing vector search for AI-powered personalization, suggestions, semantic search and anomaly detection. The latest and astronomical enhancements in accuracy and accessibility of huge language fashions (LLMs) together with BERT and OpenAI have made corporations rethink tips on how to construct related search and analytics experiences.
On this weblog, we seize engineering tales from 5 early adopters of vector search- Pinterest, Spotify, eBay, Airbnb and Doordash- who’ve built-in AI into their purposes. We hope these tales can be useful to engineering groups who’re considering via the complete lifecycle of vector search all the best way from producing embeddings to manufacturing deployments.
What’s vector search?
Vector search is a technique for effectively discovering and retrieving comparable objects from a big dataset based mostly on representations of the information in a high-dimensional house. On this context, objects may be something, comparable to paperwork, photos, or sounds, and are represented as vector embeddings. The similarity between objects is computed utilizing distance metrics, comparable to cosine similarity or Euclidean distance, which quantify the closeness of two vector embeddings.
The vector search course of normally entails:
- Producing embeddings: The place related options are extracted from the uncooked knowledge to create vector representations utilizing fashions comparable to word2vec, BERT or Common Sentence Encoder
- Indexing: The vector embeddings are organized into a knowledge construction that permits environment friendly search utilizing algorithms comparable to FAISS or HNSW
- Vector search: The place probably the most comparable objects to a given question vector are retrieved based mostly on a selected distance metric like cosine similarity or Euclidean distance
To higher visualize vector search, we will think about a 3D house the place every axis corresponds to a characteristic. The time and the place of a degree within the house is set by the values of those options. On this house, comparable objects are positioned nearer collectively and dissimilar objects are farther aside.
Embedded content material: https://gist.github.com/julie-mills/b3aefe62996c4b969b18e8abd658ce84
Given a question, we will then discover probably the most comparable objects within the dataset. The question is represented as a vector embedding in the identical house because the merchandise embeddings, and the gap between the question embedding and every merchandise embedding is computed. The merchandise embeddings with the shortest distance to the question embedding are thought of probably the most comparable.
Embedded content material: https://gist.github.com/julie-mills/d5833ea9c692edb6750e5e94749e36bf
That is clearly a simplified visualization as vector search operates in high-dimensional areas.
Within the subsequent sections, we’ll summarize 5 engineering blogs on vector search and spotlight key implementation issues. The total engineering blogs may be discovered beneath:
Pinterest: Curiosity search and discovery
Pinterest makes use of vector search for picture search and discovery throughout a number of areas of its platform, together with advisable content material on the house feed, associated pins and search utilizing a multitask studying mannequin.
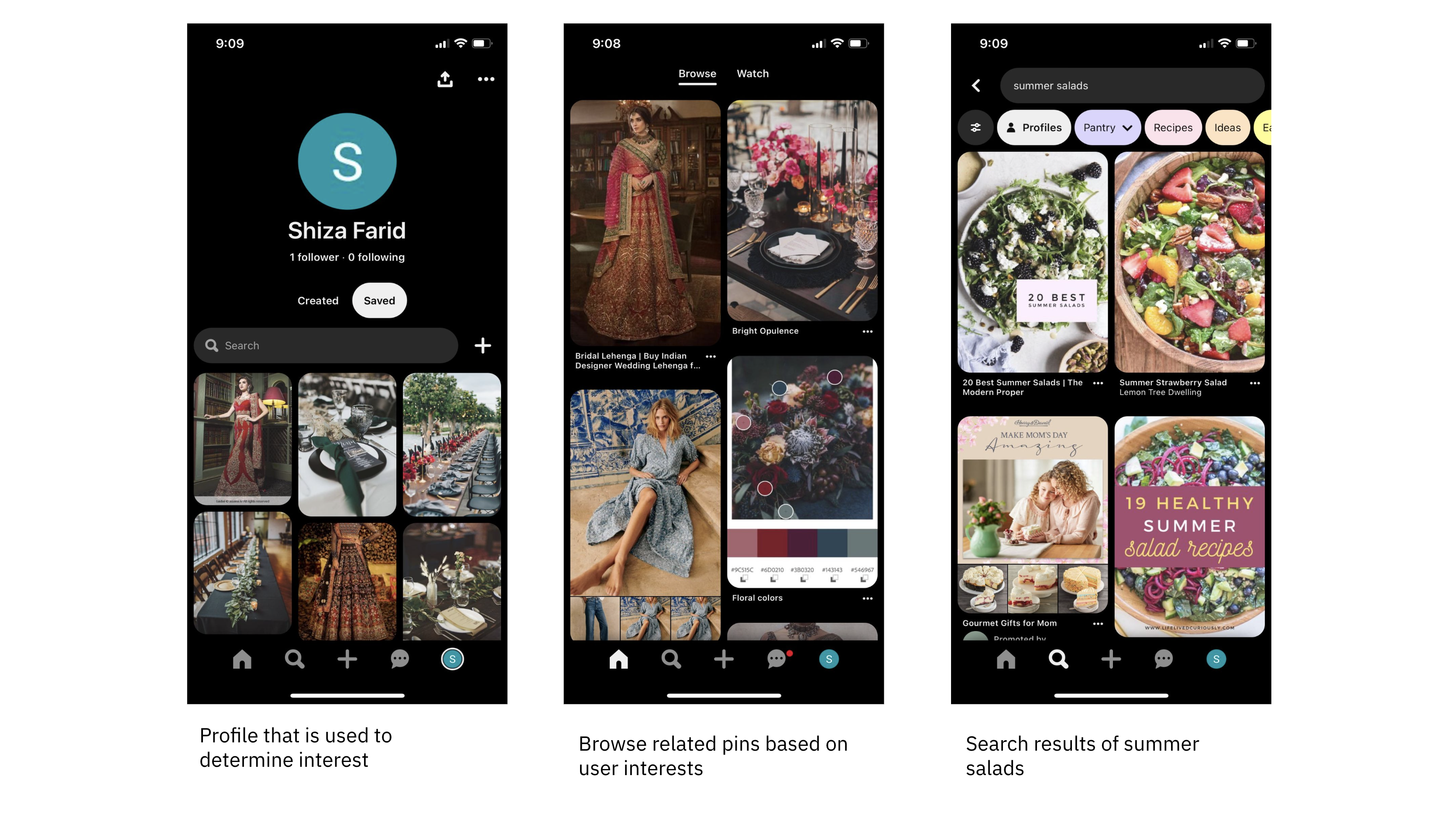
A multi-task mannequin is skilled to carry out a number of duties concurrently, typically sharing underlying representations or options, which may enhance generalization and effectivity throughout associated duties. Within the case of Pinterest, the staff skilled and used the identical mannequin to drive advisable content material on the homefeed, associated pins and search.
Pinterest trains the mannequin by pairing a customers search question (q) with the content material they clicked on or pins they saved (p). Right here is how Pinterest created the (q,p) pairs for every process:
- Associated Pins: Phrase embeddings are derived from the chosen topic (q) and the pin clicked on or saved by the consumer (p).
- Search: Phrase embeddings are created from the search question textual content (q) and the pin clicked on or saved by the consumer (p).
- Homefeed: Phrase embeddings are generated based mostly on the curiosity of the consumer (q) and the pin clicked on or saved by the consumer (p).
To acquire an general entity embedding, Pinterest averages the related phrase embeddings for associated pins, search and the homefeed.
Pinterest created and evaluated its personal supervised Pintext-MTL (multi-task studying) in opposition to unsupervised studying fashions together with GloVe, word2vec in addition to a single-task studying mannequin, PinText-SR on precision. PinText-MTL had larger precision than the opposite embedding fashions, that means that it had the next proportion of true optimistic predictions amongst all optimistic predictions.
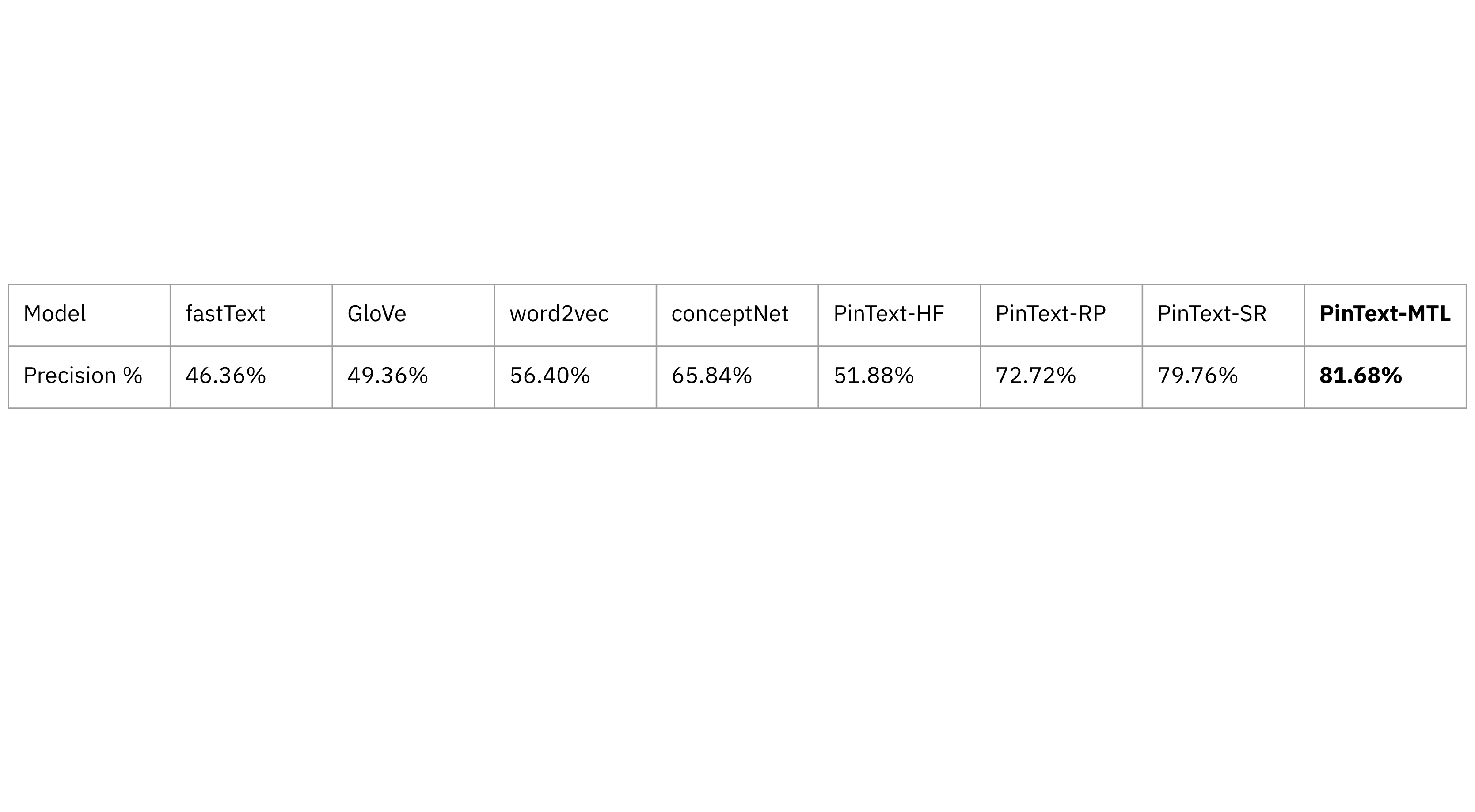
Pinterest additionally discovered that multi-task studying fashions had the next recall, or the next proportion of related situations appropriately recognized by the mannequin, making them a greater match for search and discovery.
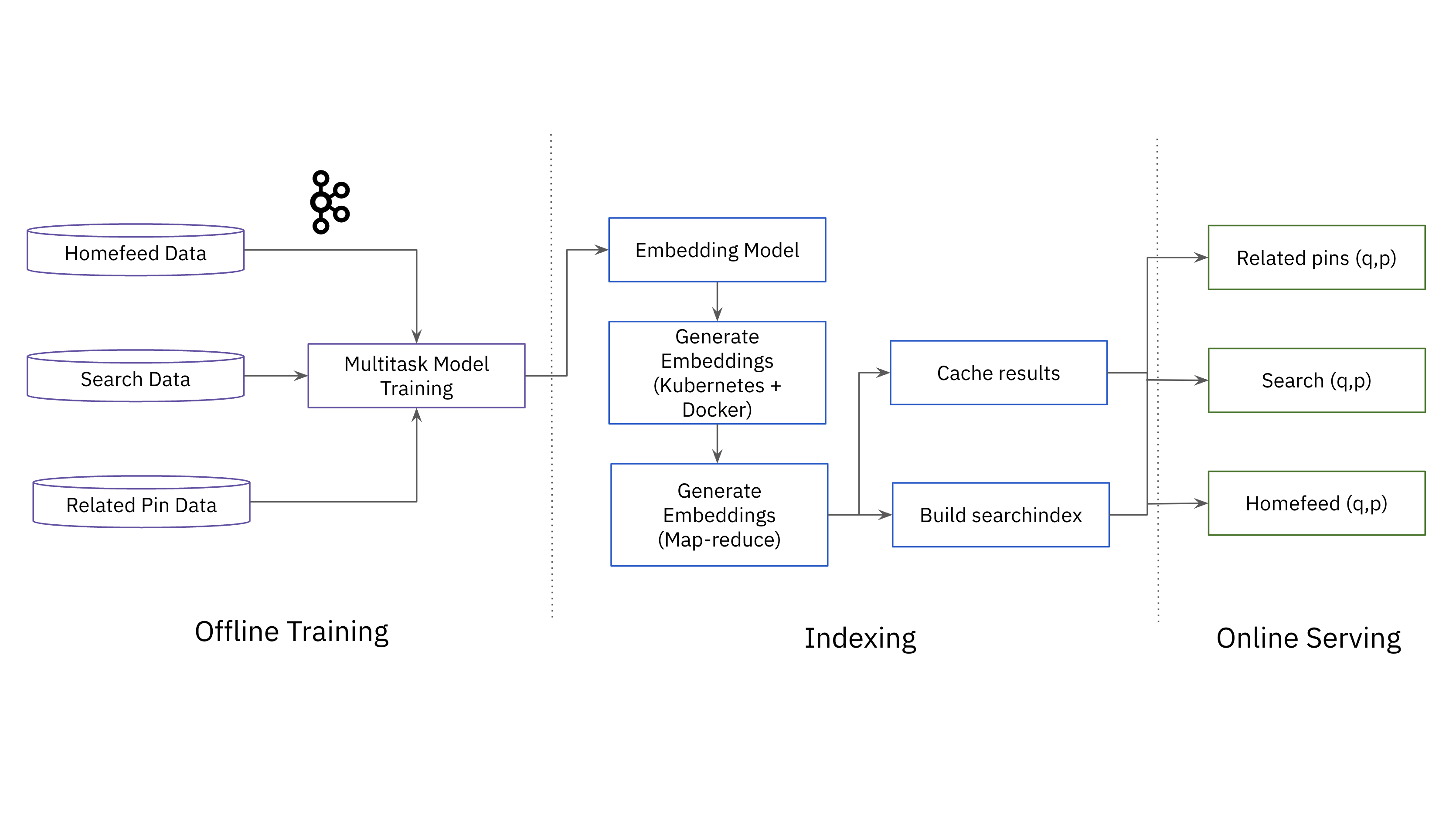
To place this all collectively in manufacturing, Pinterest has a multitask mannequin skilled on streaming knowledge from the homefeed, search and associated pins. As soon as that mannequin is skilled, vector embeddings are created in a big batch job utilizing both Kubernetes+Docker or a map-reduce system. The platform builds a search index of vector embeddings and runs a Ok-nearest neighbors (KNN) search to seek out probably the most related content material for customers. Outcomes are cached to satisfy the efficiency necessities of the Pinterest platform.
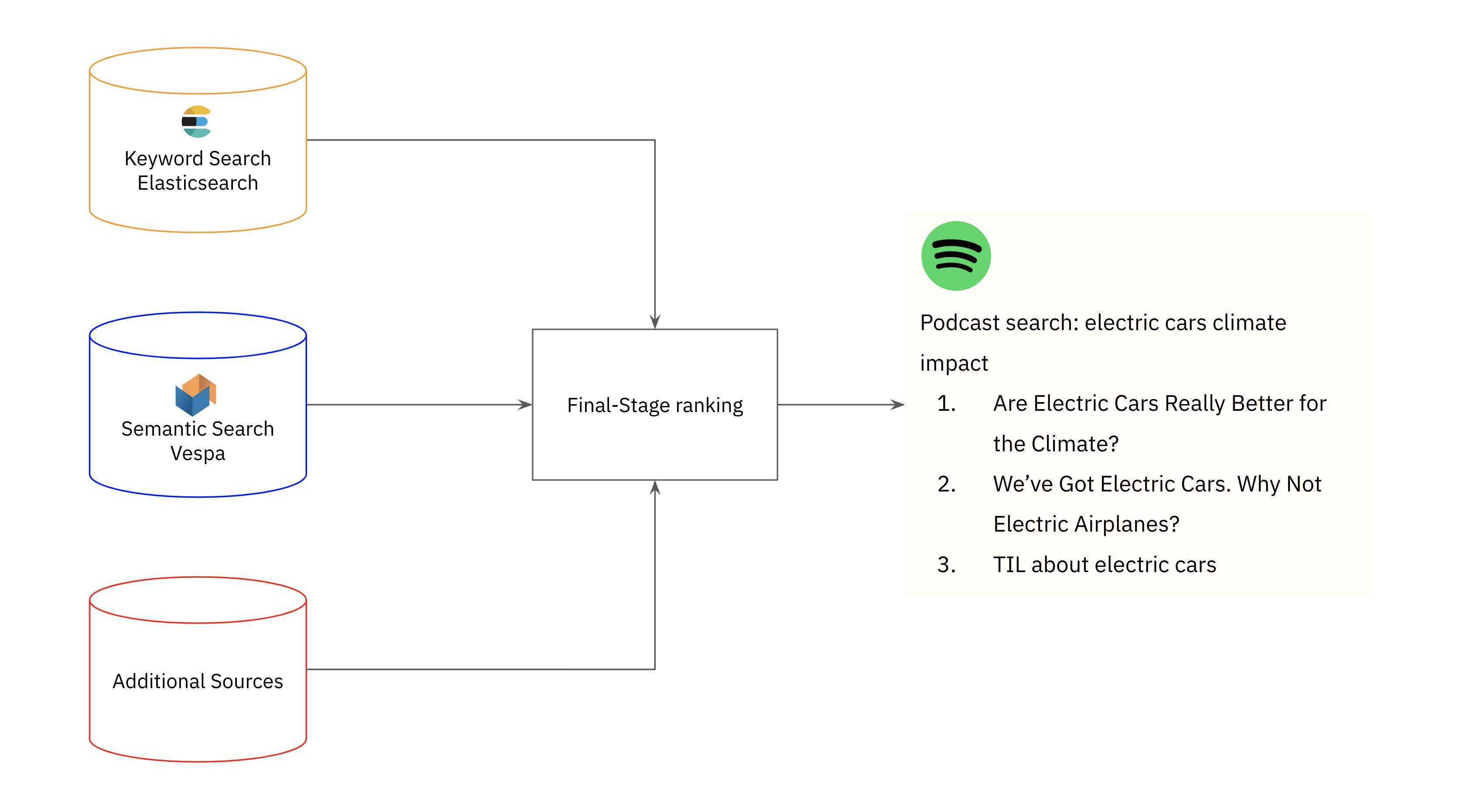
Spotify: Podcast search
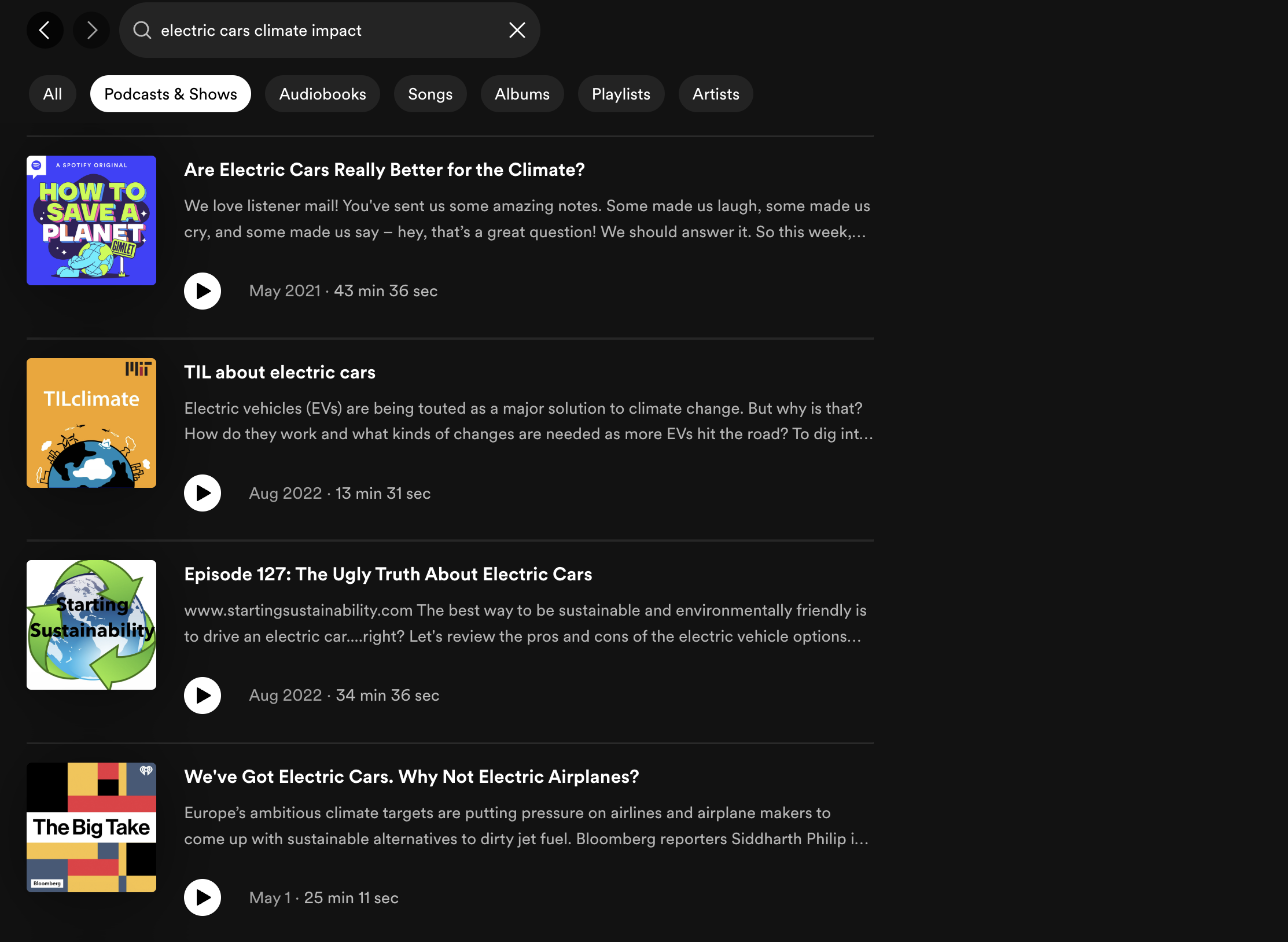
Spotify combines key phrase and semantic search to retrieve related podcast episode outcomes for customers. For example, the staff highlighted the restrictions of key phrase seek for the question “electrical vehicles local weather impression”, a question which yielded 0 outcomes regardless that related podcast episodes exist within the Spotify library. To enhance recall, the Spotify staff used Approximate Nearest Neighbor (ANN) for quick, related podcast search.
The staff generates vector embeddings utilizing the Common Sentence Encoder CMLM mannequin as it’s multilingual, supporting a world library of podcasts, and produces high-quality vector embeddings. Different fashions have been additionally evaluated together with BERT, a mannequin skilled on an enormous corpus of textual content knowledge, however discovered that BERT was higher fitted to phrase embeddings than sentence embeddings and was pre-trained solely in English.
Spotify builds the vector embeddings with the question textual content being the enter embedding and a concatenation of textual metadata fields together with title and outline for the podcast episode embeddings. To find out the similarity, Spotify measured the cosine distance between the question and episode embeddings.
To coach the bottom Common Sentence Encoder CMLM mannequin, Spotify used optimistic pairs of profitable podcast searches and episodes. They included in-batch negatives, a way highlighted in papers together with Dense Passage Retrieval for Open-Area Query Answering (DPR) and Que2Search: Quick and Correct Question and Doc Understanding for Search at Fb, to generate random detrimental pairings. Testing was additionally carried out utilizing artificial queries and manually written queries.
To include vector search into serving podcast suggestions in manufacturing, Spotify used the next steps and applied sciences:
- Index episode vectors: Spotify indexes the episode vectors offline in batch utilizing Vespa, a search engine with native assist for ANN. One of many causes that Vespa was chosen is that it might additionally incorporate metadata filtering post-search on options like episode reputation.
- On-line inference: Spotify makes use of Google Cloud Vertex AI to generate a question vector. Vertex AI was chosen for its assist for GPU inference, which is more economical when utilizing massive transformer fashions to generate embeddings, and for its question cache. After the question vector embedding is generated, it’s used to retrieve the highest 30 podcast episodes from Vespa.
Semantic search contributes to the identification of pertinent podcast episodes, but it’s unable to completely supplant key phrase search. This is because of the truth that semantic search falls in need of actual time period matching when customers search an actual episode or podcast identify. Spotify employs a hybrid search method, merging semantic search in Vespa with key phrase search in Elasticsearch, adopted by a conclusive re-ranking stage to ascertain the episodes exhibited to customers.
eBay: Picture search
Historically, serps have displayed outcomes by aligning the search question textual content with textual descriptions of things or paperwork. This technique depends extensively on language to deduce preferences and isn’t as efficient in capturing parts of favor or aesthetics. eBay introduces picture search to assist customers discover related, comparable objects that meet the model they’re in search of.
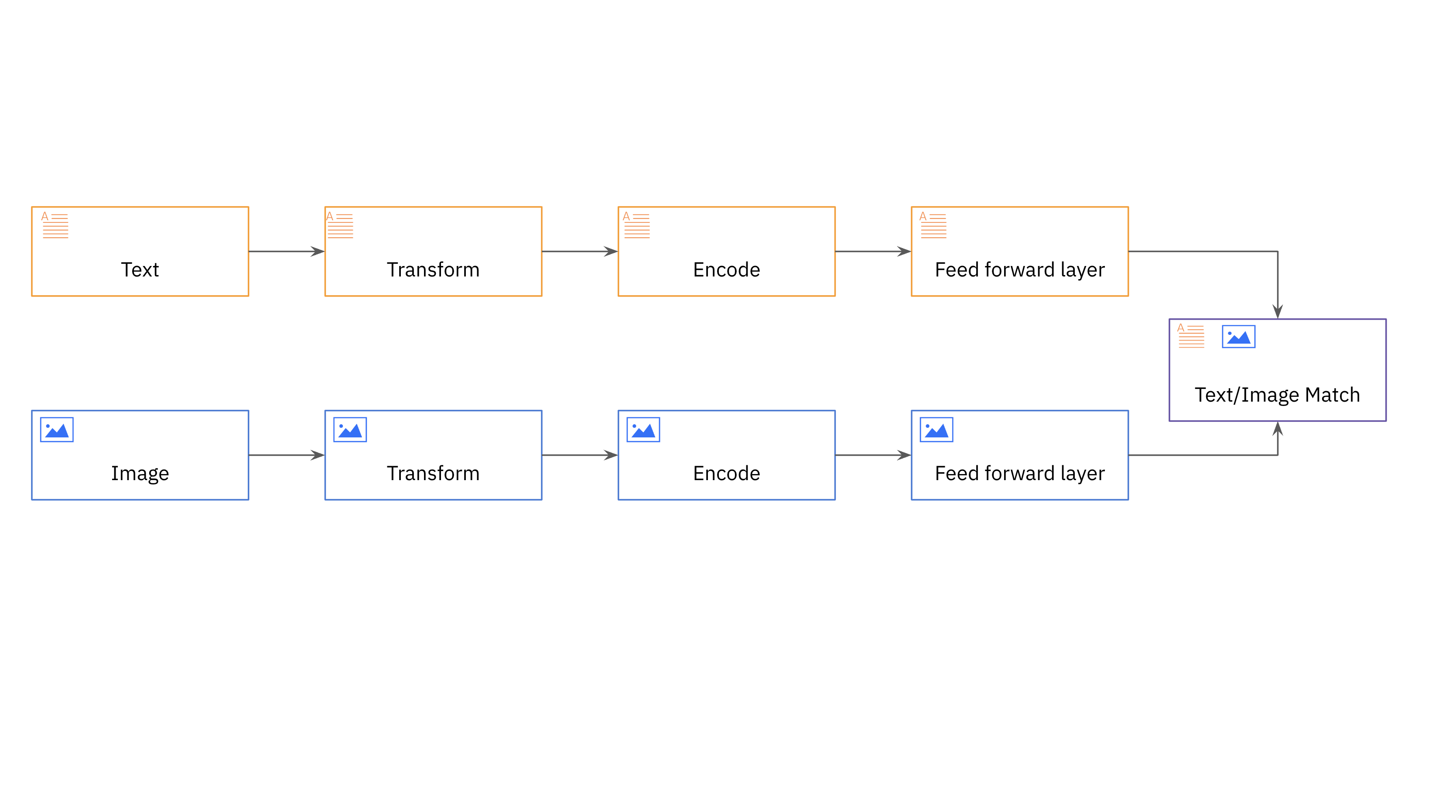
eBay makes use of a multi-modal mannequin which is designed to course of and combine knowledge from a number of modalities or enter sorts, comparable to textual content, photos, audio, or video, to make predictions or carry out duties. eBay incorporates each textual content and pictures into its mannequin, producing picture embeddings using a Convolutional Neural Community (CNN) mannequin, particularly Resnet-50, and title embeddings utilizing a text-based mannequin comparable to BERT. Each itemizing is represented by a vector embedding that mixes each the picture and title embeddings.
As soon as the multi-modal mannequin is skilled utilizing a big dataset of image-title itemizing pairs and just lately offered listings, it’s time to put it into manufacturing within the web site search expertise. Because of the massive variety of listings at eBay, the information is loaded in batches to HDFS, eBay’s knowledge warehouse. eBay makes use of Apache Spark to retrieve and retailer the picture and related fields required for additional processing of listings, together with producing itemizing embeddings. The itemizing embeddings are printed to a columnar retailer comparable to HBase which is sweet at aggregating large-scale knowledge. From HBase, the itemizing embedding is listed and served in Cassini, a search engine created at eBay.
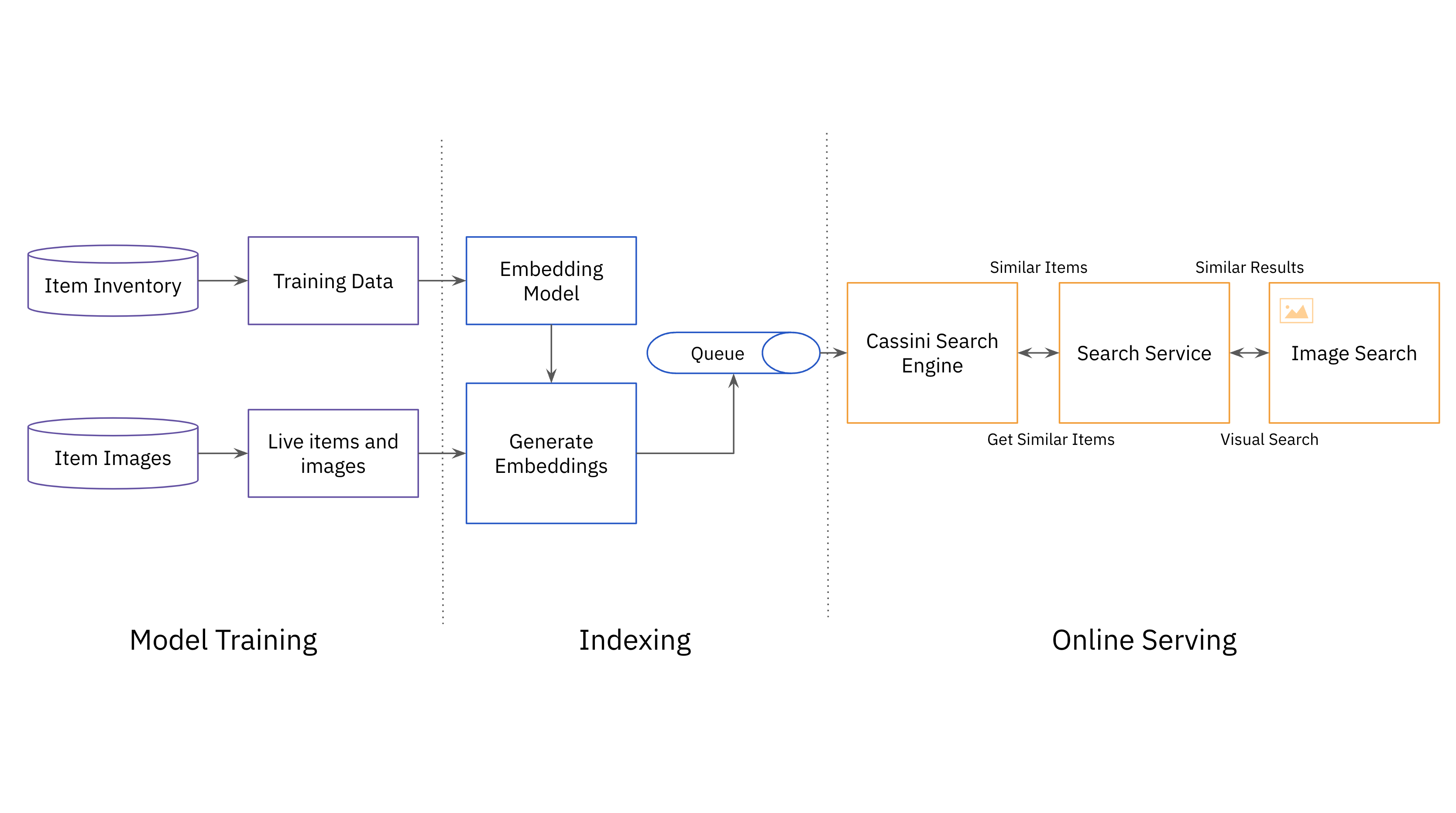
The pipeline is managed utilizing Apache Airflow, which is able to scaling even when there’s a excessive amount and complexity of duties. It additionally offers assist for Spark, Hadoop, and Python, making it handy for the machine studying staff to undertake and make the most of.
Visible search permits customers to seek out comparable kinds and preferences within the classes of furnishings and residential decor, the place model and aesthetics are key to buy selections. Sooner or later, eBay plans to broaden visible search throughout all classes and likewise assist customers uncover associated objects to allow them to set up the identical appear and feel throughout their residence.
AirBnb: Actual-time customized listings
Search and comparable listings options drive 99% of bookings on the AirBnb web site. AirBnb constructed a itemizing embedding approach to enhance comparable itemizing suggestions and supply real-time personalization in search rankings.
AirBnb realized early on that they might broaden the appliance of embeddings past simply phrase representations, encompassing consumer behaviors together with clicks and bookings as nicely.
To coach the embedding fashions, AirBnb included over 4.5M energetic listings and 800 million search classes to find out the similarity based mostly on what listings a consumer clicks and skips in a session. Listings that have been clicked by the identical consumer in a session are pushed nearer collectively; listings that have been skipped by the consumer are pushed additional away. The staff settled on the dimensionality of an inventory embedding of d=32 given the tradeoff between offline efficiency and reminiscence wanted for on-line serving.
Embedded content material: https://youtu.be/aWjsUEX7B1I
AirBnb discovered that sure listings traits don’t require studying, as they are often immediately obtained from metadata, comparable to worth. Nevertheless, attributes like structure, model, and ambiance are significantly tougher to derive from metadata.
Earlier than transferring to manufacturing, AirBnb validated their mannequin by testing how nicely the mannequin advisable listings {that a} consumer truly booked. The staff additionally ran an A/B take a look at evaluating the prevailing listings algorithm in opposition to the vector embedding-based algorithm. They discovered that the algorithm with vector embeddings resulted in a 21% uptick in CTR and 4.9% enhance in customers discovering an inventory that they booked.
The staff additionally realized that vector embeddings could possibly be used as a part of the mannequin for real-time personalization in search. For every consumer, they collected and maintained in actual time, utilizing Kafka, a short-term historical past of consumer clicks and skips within the final two weeks. For each search carried out by the consumer, they ran two similarity searches:
- based mostly on the geographic markets that have been just lately searched after which
- the similarity between the candidate listings and those the consumer has clicked/skipped
Embeddings have been evaluated in offline and on-line experiments and have become a part of the real-time personalization options.
Doordash: Personalised retailer feeds
Doordash has all kinds of shops that customers can select to order from and with the ability to floor probably the most related shops utilizing customized preferences improves search and discovery.
Doordash needed to use latent info to its retailer feed algorithms utilizing vector embeddings. This might allow Doordash to uncover similarities between shops that weren’t well-documented together with if a retailer has candy objects, is taken into account stylish or options vegetarian choices.
Doordash used a spinoff of word2vec, an embedding mannequin utilized in pure language processing, known as store2vec that it tailored based mostly on present knowledge. The staff handled every retailer as a phrase and shaped sentences utilizing the checklist of shops seen throughout a single consumer session, with a most restrict of 5 shops per sentence. To create consumer vector embeddings, Doordash summed the vectors of the shops from which customers positioned orders previously 6 months or as much as 100 orders.
For example, Doordash used vector search to seek out comparable eating places for a consumer based mostly on their latest purchases at standard, stylish joints 4505 Burgers and New Nagano Sushi in San Francisco. Doordash generated an inventory of comparable eating places measuring the cosine distance from the consumer embedding to retailer embeddings within the space. You may see that the shops that have been closest in cosine distance embrace Kezar Pub and Picket Charcoal Korean Village BBQ.

Doordash included store2vec distance characteristic as one of many options in its bigger advice and personalization mannequin. With vector search, Doordash was in a position to see a 5% enhance in click-through-rate. The staff can be experimenting with new fashions like seq2seq, mannequin optimizations and incorporating real-time onsite exercise knowledge from customers.
Key issues for vector search
Pinterest, Spotify, eBay, Airbnb and Doordash create higher search and discovery experiences with vector search. Many of those groups began out utilizing textual content search and located limitations with fuzzy search or searches of particular kinds or aesthetics. In these eventualities, including vector search to the expertise made it simpler to seek out related, and infrequently customized, podcasts, pillows, leases, pins and eateries.
There are a number of selections that these corporations made which can be price calling out when implementing vector search:
- Embedding fashions: Many began out utilizing an off-the-shelf mannequin after which skilled it on their very own knowledge. In addition they acknowledged that language fashions like word2vec could possibly be utilized by swapping phrases and their descriptions with objects and comparable objects that have been just lately clicked. Groups like AirBnb discovered that utilizing derivatives of language fashions, somewhat than picture fashions, may nonetheless work nicely for capturing visible similarities and variations.
- Coaching: Many of those corporations opted to coach their fashions on previous buy and click on via knowledge, making use of present large-scale datasets.
- Indexing: Whereas many corporations adopted ANN search, we noticed that Pinterest was in a position to mix metadata filtering with KNN seek for effectivity at scale.
- Hybrid search: Vector search not often replaces textual content search. Many occasions, like in Spotify’s instance, a last rating algorithm is used to find out whether or not vector search or textual content search generated probably the most related end result.
- Productionizing: We’re seeing many groups use batch-based methods to create the vector embeddings, on condition that these embeddings are not often up to date. They make use of a distinct system, continuously Elasticsearch, to compute the question vector embedding reside and incorporate real-time metadata of their search.
Rockset, a real-time search and analytics database, just lately added assist for vector search. Give vector search on Rockset a attempt for real-time personalization, suggestions, anomaly detection and extra by beginning a free trial with $300 in credit at this time.
[ad_2]