
[ad_1]
Within the earlier installment of this collection, we delved into the intricacies of the PaLM API and its seamless integration with LangChain. The good benefit of LangChain is the pliability to swap out the massive language mannequin (LLM) with solely slight adjustments to our code. As now we have seen, inside the LangChain framework, the LLM is reworked right into a easy “hyperlink” within the chain, facilitating simple replacements.
LangChain helps a number of use instances together with summarization, query answering, sentiment evaluation, and extra. Whereas the final tutorial explored the fundamentals of LangChain and the Google PaLM API, this text will take a look at extracting solutions from a PDF by way of the mix of the LangChain SDK and the PaLM API.
Let’s get began.
Obtain the PDF
Make a listing named information and obtain the PDF of Joe Biden’s 2023 State of the Union tackle from the EU parliament web site.
wget -O information/sotu.pdf https://www.europarl.europa.eu/RegData/etudes/ATAG/2023/739359/EPRS_ATA(2023)739359_EN.pdf
We’ll use the information on this PDF to construct our Q&A app.
Import Python modules
Begin by importing the Python modules listed under.
from langchain.llms import GooglePalm from langchain.embeddings import GooglePalmEmbeddings from langchain.text_splitter import CharacterTextSplitter from langchain.vectorstores import FAISS from langchain.document_loaders import PyPDFLoader from langchain.chains.question_answering import load_qa_chain
Load the doc with PyPDFLoader.
loader = PyPDFLoader ("./information/sotu.pdf")
paperwork = loader.load()
Convert the content material into uncooked textual content.
raw_text=""
for i, doc in enumerate(paperwork):
textual content = doc.page_content
if textual content:
raw_text += textual content
Create chunks of textual content
We’ll then create chunks of 200 characters from the uncooked textual content. This helps pace up the queries by loading smaller chunks of related information.
text_splitter = CharacterTextSplitter( separator = "n", chunk_size = 200, chunk_overlap = 40, length_function = len, ) texts = text_splitter.split_text(raw_text)
Generate embeddings
Let’s set the textual content embeddings mannequin to Google PaLM.
embeddings = GooglePalmEmbeddings()
We are actually able to generate the embeddings for all of the chunks of textual content we created.
docsearch = FAISS.from_texts(texts, embeddings)
FAISS (Fb AI Similarity Search) is a well-liked library from Fb for performing in-memory similarity searches. Since our doc is small, we are able to depend on this library. For bigger paperwork, utilizing a vector database is really useful.
Create a Q&A series
We’ll now create a Q&A series that can be handed on to the PaLM mannequin.
chain = load_qa_chain(GooglePalm(), chain_type="stuff")
The method of the “stuff” doc chain is simple. It entails compiling an inventory of paperwork, inputting them right into a immediate, after which submitting that immediate to an LLM. This course of is helpful when coping with a small variety of paperwork that aren’t too intensive.
It’s time to fireside up the primary query.
question = "Clarify who created the doc and what's the goal?" docs = docsearch.similarity_search(question) print(chain.run(input_documents=docs, query=question).strip())
 IDG
IDGThe reply appears on course. I examined this mannequin with a couple of extra questions.
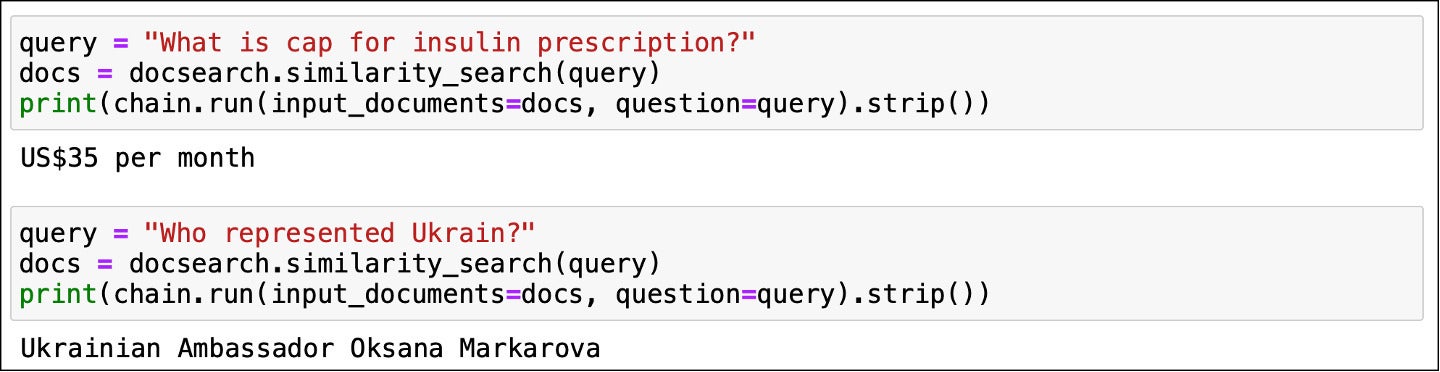 IDG
IDGFull PaLM 2 Q&A instance
Beneath is the entire code you possibly can run in your personal atmosphere or in Google Colab.
from langchain.llms import GooglePalm
from langchain.embeddings import GooglePalmEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.document_loaders import PyPDFLoader
from langchain.chains.question_answering import load_qa_chain
loader = PyPDFLoader ("./information/sotu.pdf")
paperwork = loader.load()
raw_text=""
for i, doc in enumerate(paperwork):
textual content = doc.page_content
if textual content:
raw_text += textual content
text_splitter = CharacterTextSplitter(
separator = "n",
chunk_size = 200,
chunk_overlap = 40,
length_function = len,
)
texts = text_splitter.split_text(raw_text)
embeddings = GooglePalmEmbeddings()
docsearch = FAISS.from_texts(texts, embeddings)
question = "Clarify who created the doc and what's the goal?"
docs = docsearch.similarity_search(question)
print(chain.run(input_documents=docs, query=question).strip())
question = "What's cap for insulin prescription?"
docs = docsearch.similarity_search(question)
print(chain.run(input_documents=docs, query=question).strip())
question = "Who represented Ukrain?"
docs = docsearch.similarity_search(question)
print(chain.run(input_documents=docs, query=question).strip())
Whereas this was a quick and easy train, it reveals how we are able to dramatically improve the accuracy of our PaLM 2 mannequin by offering it with context from customized information sources (on this case from the PDF). Right here LangChain made this integration easy by incorporating a similarity search (which retrieved the related components of the doc) as context for the immediate. LangChain makes it straightforward to incorporate customized information sources and similarity search as components of the pipelines that we construct.
Within the subsequent article of this collection, we’ll construct a summarization app from the identical PDF. Keep tuned.
Copyright © 2023 IDG Communications, Inc.
[ad_2]