
[ad_1]
As the dimensions and complexity of microservices and distributed purposes continues to develop, prospects are searching for steering for constructing cost-efficient infrastructure supporting operational analytics use circumstances. Operational analytics is a well-liked use case with Amazon OpenSearch Service. Just a few of the defining traits of those use circumstances are ingesting a excessive quantity of time collection knowledge and a comparatively low quantity of querying, alerting, and working analytics on ingested knowledge for real-time insights. Though OpenSearch Service is able to ingesting petabytes of information throughout storage tiers, you continue to need to provision capability emigrate between sizzling and heat tiers. This provides to the price of provisioned OpenSearch Service domains.
The time collection knowledge usually accommodates logs or telemetry knowledge from numerous sources with completely different values and wishes. That’s, logs from some sources must be accessible in a sizzling storage tier longer, whereas logs from different sources can tolerate a delay in querying and different necessities. Till now, prospects have been constructing exterior ingestion techniques with the Amazon Kinesis household of providers, Amazon Easy Queue Service (Amazon SQS), AWS Lambda, customized code, and different comparable options. Though these options allow ingestion of operational knowledge with numerous necessities, they add to the price of ingestion.
Generally, operational analytics workloads use anomaly detection to help area operations. This assumes that the information is already current in OpenSearch Service and the price of ingestion is already borne.
With the addition of some current options of Amazon OpenSearch Ingestion, a totally managed serverless pipeline for OpenSearch Service, you’ll be able to successfully handle every of those value factors and construct an economical answer. On this submit, we define an answer that does the next:
- Makes use of conditional routing of Amazon OpenSearch Ingestion to separate logs with particular attributes and retailer these, for instance, in Amazon OpenSearch Service and archive all occasions in Amazon S3 to question with Amazon Athena
- Makes use of in-stream anomaly detection with OpenSearch Ingestion, thereby eradicating the associated fee related to compute wanted for anomaly detection after ingestion
On this submit, we use a VPC move logs use case to reveal the answer. The answer and sample offered on this submit is equally relevant to bigger operational analytics and observability use circumstances.
Answer overview
We use VPC move logs to seize IP visitors and set off processing notifications to the OpenSearch Ingestion pipeline. The pipeline filters the information, routes the information, and detects anomalies. The uncooked knowledge might be saved in Amazon S3 for archival functions, then the pipeline will detect anomalies within the knowledge in near-real time utilizing the Random Lower Forest (RCF) algorithm and ship these knowledge information to OpenSearch Service. The uncooked knowledge saved in Amazon S3 may be inexpensively retained for an prolonged time period utilizing tiered storage and queried utilizing the Athena question engine, and likewise visualized utilizing Amazon QuickSight or different knowledge visualization providers. Though this walkthrough makes use of VPC move log knowledge, the identical sample applies to be used with AWS CloudTrail, Amazon CloudWatch, any log recordsdata in addition to any OpenTelemetry occasions, and customized producers.
The next is a diagram of the answer that we configure on this submit.

Within the following sections, we offer a walkthrough for configuring this answer.
The patterns and procedures offered on this submit have been validated with the present model of OpenSearch Ingestion and the Knowledge Prepper open-source venture model 2.4.
Stipulations
Full the next prerequisite steps:
- We might be utilizing a VPC for demonstration functions for producing knowledge. Arrange the VPC move logs to publish logs to an S3 bucket in textual content format. To optimize S3 storage prices, create a lifecycle configuration on the S3 bucket to transition the VPC move logs to completely different tiers or expire processed logs. Make a remark of the S3 bucket title you configured to make use of in later steps.
- Arrange an OpenSearch Service area. Make a remark of the area URL. The area may be both public or VPC based mostly, which is the popular configuration.
- Create an S3 bucket for storing archived occasions, and make an observation of S3 bucket title. Configure a resource-based coverage permitting OpenSearch Ingestion to archive logs and Athena to learn the logs.
- Configure an AWS Identification and Entry Administration (IAM) function or separate IAM roles permitting OpenSearch Ingestion to work together with Amazon SQS and Amazon S3. For directions, consult with Configure the pipeline function.
- Configure Athena or validate that Athena is configured in your account. For directions, consult with Getting began.
Configure an SQS notification
VPC move logs will write knowledge in Amazon S3. After every file is written, Amazon S3 will ship an SQS notification to inform the OpenSearch Ingestion pipeline that the file is prepared for processing.
If the information is already saved in Amazon S3, you should use the S3 scan functionality for a one-time or scheduled loading of information by way of the OpenSearch Ingestion pipeline.
Use AWS CloudShell to situation the next instructions to create the SQS queues VpcFlowLogsNotifications and VpcFlowLogsNotifications-DLQ that we use for this walkthrough.
Create a dead-letter queue with the next code
Create an SQS queue to obtain occasions from Amazon S3 with the next code:
To configure the S3 bucket to ship occasions to the SQS queue, use the next code (present the title of your S3 bucket used for storing VPC move logs):
Create the OpenSearch Ingestion pipeline
Now that you’ve configured Amazon SQS and the S3 bucket notifications, you’ll be able to configure the OpenSearch Ingestion pipeline.
- On the OpenSearch Service console, select Pipelines beneath Ingestion within the navigation pane.
- Select Create pipeline.
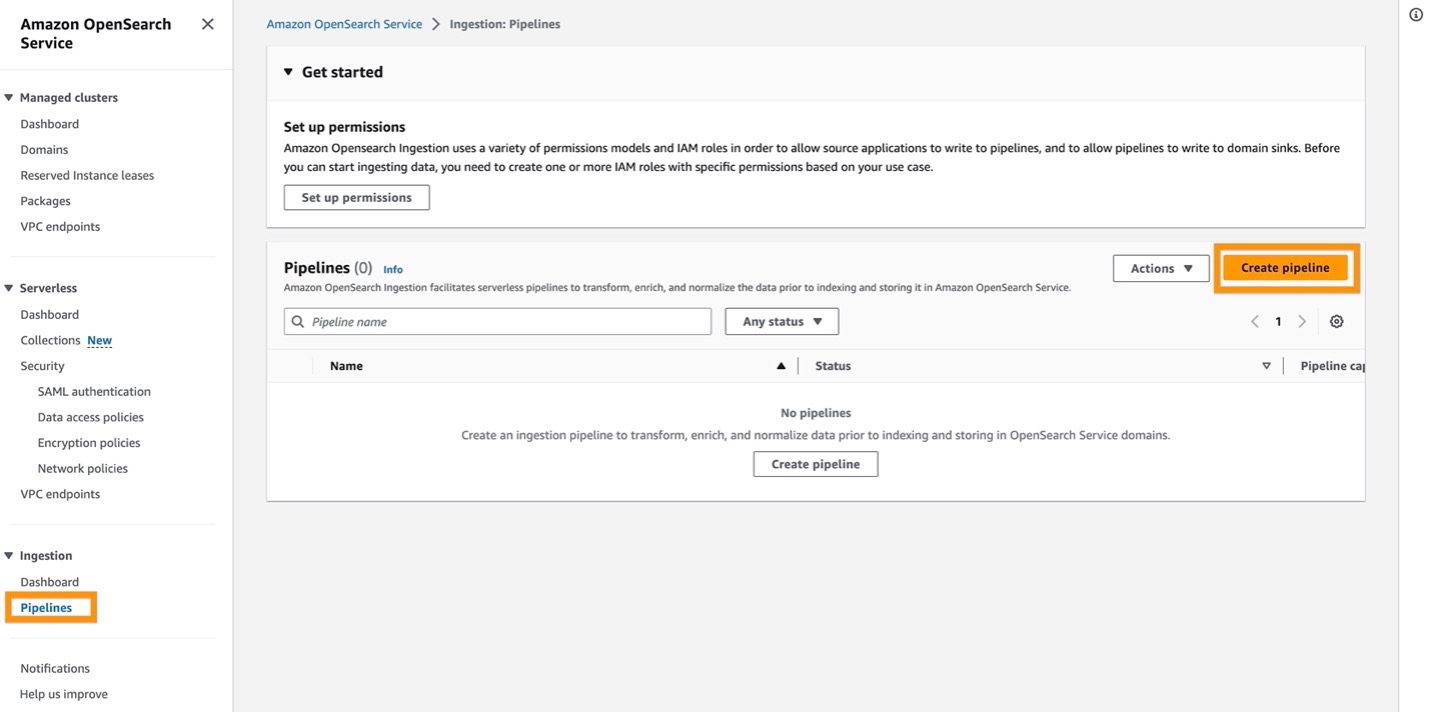
- For Pipeline title, enter a reputation (for this submit, we use
stream-analytics-pipeline). - For Pipeline configuration, enter the next code:
Change the variables within the previous code with sources in your account:
-
__SQS_QUEUE_URL__– URL of Amazon SQS for Amazon S3 occasions__STS_ROLE_ARN__– AWS Safety Token Service (AWS STS) roles for sources to imagine__AWS_S3_BUCKET_ARCHIVE__– S3 bucket for archiving processed occasions__AMAZON_OPENSEARCH_DOMAIN_URL__– URL of OpenSearch Service area__REGION__– Area (for instance, us-east-1)
- Within the Community settings part, specify your community entry. For this walkthrough, we’re utilizing VPC entry. We supplied the VPC and personal subnet places which have connectivity with the OpenSearch Service area and safety teams.
- Depart the opposite settings with default values, and select Subsequent.

- Assessment the configuration adjustments and select Create pipeline.
It can take a couple of minutes for OpenSearch Service to provision the surroundings. Whereas the surroundings is being provisioned, we’ll stroll you thru the pipeline configuration. Entry-pipeline listens for SQS notifications about newly arrived recordsdata and triggers the studying of VPC move log compressed recordsdata:
The pipeline branches into two sub-pipelines. The primary shops unique messages for archival functions in Amazon S3 in read-optimized Parquet format; the opposite applies analytics routes occasions to the OpenSearch Service area for quick querying and alerting:
The pipeline archive-pipeline aggregates messages in 50 MB chunks or each 60 seconds and writes a Parquet file to Amazon S3 with the schema inferred from the message. Additionally, a prefix is added to assist with partitioning and question optimization when studying a group of recordsdata utilizing Athena.
Now that we’ve reviewed the fundamentals, we deal with the pipeline that detects anomalies and sends solely high-value messages that deviate from the norm to OpenSearch Service. It additionally shops Web Management Message Protocols (ICMP) messages in OpenSearch Service.
We utilized a grok processor to parse the message utilizing a predefined regex for parsing VPC move logs, and likewise tagged all unparsable messages with the grok_match_failure tag, which we use to take away headers and different information that may’t be parsed:
We then routed all messages with the protocol identifier 1 (ICMP) to icmp-pipeline and all messages to analytics-pipeline for anomaly detection:
Within the analytics pipeline, we dropped all information that may’t be parsed utilizing the hasTags technique based mostly on the tag that we assigned on the time of parsing. We additionally eliminated all information that don’t accommodates helpful knowledge for anomaly detection.
Then we utilized probabilistic sampling utilizing the tail_sampler processor for all accepted messages grouped by supply and vacation spot addresses and despatched these to the sink with all messages that weren’t accepted. This helps cut back the amount of messages throughout the chosen cardinality keys, with a deal with all messages that weren’t accepted, and retains a pattern illustration of messages that have been accepted.
Then we used the anomaly detector processor to determine anomalies throughout the cardinality key pairs or supply and vacation spot addresses in our instance. The anomaly detector processor creates and trains RCF fashions for a hashed worth of keys, then makes use of these fashions to find out whether or not newly arriving messages have an anomaly based mostly on the skilled knowledge. In our demonstration, we use bytes knowledge to detect anomalies:
We set verbose:true to instruct the detector to emit the message each time an anomaly is detected. Additionally, for this walkthrough, we used a non-default sample_size for coaching the mannequin.
When anomalies are detected, the anomaly detector returns an entire document and provides
"deviation_from_expected":worth,"grade":worth attributes that signify the deviation worth and severity of the anomaly. These values can be utilized to find out routing of such messages to OpenSearch Service, and use per-document monitoring capabilities in OpenSearch Service to alert on particular situations.
Presently, OpenSearch Ingestion creates as much as 5,000 distinct fashions based mostly on cardinality key values per compute unit. This restrict is noticed utilizing the anomaly_detector.RCFInstances.worth CloudWatch metric. It’s vital to pick a cardinality key-value pair to keep away from exceeding this constraint. As growth of the Knowledge Prepper open-source venture and OpenSearch Ingestion continues, extra configuration choices might be added to supply better flexibility round mannequin coaching and reminiscence administration.
The OpenSearch Ingestion pipeline exposes the anomaly_detector.cardinalityOverflow.depend metric by way of CloudWatch. This metric signifies numerous key worth pairs that weren’t run by the anomaly detection processor throughout a time period as the utmost variety of RCFInstances per compute unit was reached. To keep away from this constraint, numerous compute items may be scaled out to offer further capability for internet hosting further situations of RCFInstances.
Within the final sink, the pipeline writes information with detected anomalies together with deviation_from_expected and grade attributes to the OpenSearch Service area:
As a result of solely anomaly information are being routed and written to the OpenSearch Service area, we’re in a position to considerably cut back the scale of our area and optimize the price of our pattern observability infrastructure.
One other sink was used for storing all ICMP information in a separate index within the OpenSearch Service area:
Question archived knowledge from Amazon S3 utilizing Athena
On this part, we overview the configuration of Athena for querying archived occasions knowledge saved in Amazon S3. Full the next steps:
- Navigate to the Athena question editor and create a brand new database known as
vpc-flow-logs-archive-database utilizing the next command:
- 2. On the Database menu, select
vpc-flow-logs-archive. - Within the question editor, enter the next command to create a desk (present the S3 bucket used for archiving processed occasions). For simplicity, for this walkthrough, we create a desk with out partitions.
- Run the next question to validate which you could question the archived VPC move log knowledge:
As a result of archived knowledge is saved in its unique format, it helps keep away from points associated to format conversion. Athena will question and show information within the unique format. Nonetheless, it’s very best to work together solely with a subset of columns or elements of the messages. You need to use the regexp_split perform in Athena to separate the message within the columns and retrieve sure columns. Run the next question to see the supply and vacation spot handle groupings from the VPC move log knowledge:
This demonstrated which you could question all occasions utilizing Athena, the place archived knowledge in its unique uncooked format is used for the evaluation. Athena is priced per knowledge scanned. As a result of the information is saved in a read-optimized format and partitioned, it permits additional cost-optimization round on-demand querying of archived streaming and observability knowledge.
Clear up
To keep away from incurring future prices, delete the next sources created as a part of this submit:
- OpenSearch Service area
- OpenSearch Ingestion pipeline
- SQS queues
- VPC move logs configuration
- All knowledge saved in Amazon S3
Conclusion
On this submit, we demonstrated the best way to use OpenSearch Ingestion pipelines to construct a cost-optimized infrastructure for log analytics and observability occasions. We used routing, filtering, aggregation, and anomaly detection in an OpenSearch Ingestion pipeline, enabling you to downsize your OpenSearch Service area and create a cost-optimized observability infrastructure. For our instance, we used an information pattern with 1.5 million occasions with a pipeline distilling to 1,300 occasions with predicted anomalies based mostly on supply and vacation spot IP pairs. This metric demonstrates that the pipeline recognized that lower than 0.1% of occasions have been of excessive significance, and routed these to OpenSearch Service for visualization and alerting wants. This interprets to decrease useful resource utilization in OpenSearch Service domains and might result in provisioning of smaller OpenSearch Service environments.
We encourage you to make use of OpenSearch Ingestion pipelines to create your purpose-built and cost-optimized observability infrastructure that makes use of OpenSearch Service for storing and alerting on high-value occasions. When you have feedback or suggestions, please depart them within the feedback part.
In regards to the Authors
 Mikhail Vaynshteyn is a Options Architect with Amazon Net Providers. Mikhail works with healthcare and life sciences prospects to construct options that assist enhance sufferers’ outcomes. Mikhail makes a speciality of knowledge analytics providers.
Mikhail Vaynshteyn is a Options Architect with Amazon Net Providers. Mikhail works with healthcare and life sciences prospects to construct options that assist enhance sufferers’ outcomes. Mikhail makes a speciality of knowledge analytics providers.
 Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search purposes and options. Muthu is within the matters of networking and safety, and relies out of Austin, Texas.
Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search purposes and options. Muthu is within the matters of networking and safety, and relies out of Austin, Texas.
[ad_2]